

Introduction
It’s very likely you have been running a GKE cluster at the version v1.15 for many months without issues and then -suddenly- the logs stopped being received. You are using the default logging system the system provides, so you then check the GCP status website but everything is running fine. You also know you have not modified anything on the cluster before the log stop, but at the same time you guess it has to be something on your side (on our case because it’s not happening on some other projects we manage).
If the above story is familiar to you continue reading as this article will cover from how to detect it, to the solution that will make your cluster logs being received again.
1. Symptoms
-
- – The very first symptom you may notice is the sudden, complete absence of logs in Stackdriver, which should be coming -as usual- from your cluster’s pods.
- – Beside the previous fact, you will additionally find out you have no Fluentd agents anymore in your cluster.
$ kubectl get daemonset -n kube-system | grep -i fluentd
- – On the other hand, all the nodes of your cluster have the label beta.kubernetes.io/fluentd-ds-ready=true, which is required for the Fluentd agents to know to which nodes should be deployed.
$ kubectl get nodes NAME STATUS ROLES AGE VERSION gke-cluster-node-93c020-7rjq Ready none 14h v1.15.11-gke.15 gke-cluster-node-93c020-9w22 Ready none 23h v1.15.11-gke.15 gke-cluster-node-93c020-jdbt Ready none 47h v1.15.11-gke.15 gke-cluster-node-93c020-jvcl Ready none 3h17m v1.15.11-gke.15 $ kubectl describe node gke-cluster-node-93c020-7rjq | grep -i fluentd-ds-ready beta.kubernetes.io/fluentd-ds-ready=true $ # Do the same for the remaining nodes in order to ensure all of them are properly labeled - – Your GKE cluster is currently at the version v1.15 or greater.
2. Diagnose
What is currently happening is GCP forcibly deprecating the legacy monitoring/logging system. The replacement is called Cloud Operations for GKE which (for our use case) does basically the same. Once said that, keep in mind there are a few differences you should take care about when searching (such as metric names changes), and that you will find them all on the migration guide.
3. Treatment
Label the cluster nodes
If you found on previous steps that your cluster nodes were not labeled, do it now!
$ kubectl label node $NODE_NAME beta.kubernetes.io/fluentd-ds-ready=true
Get your cluster’s name
List the available clusters.
$ gcloud container clusters list NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS my-cluster europe-east1-a 1.15.12-gke.2 34.35.36.37 n1-standard-2 1.15.11-gke.15 4 RUNNING
Disable the logging service for your cluster
Update your cluster’s config in order to set the logging service to none.
$ gcloud container clusters update my-cluster --logging-service none
Enable again the logging service for your cluster
Update your cluster’s config in order to set the logging service to the default one.
$ gcloud container clusters update my-cluster --logging-service logging.googleapis.com
WARNING: You will get an error telling you that enabling it is not possible due to the deprecation. This is the way we finally realized where the problem was. Just move on, you are on the right way.
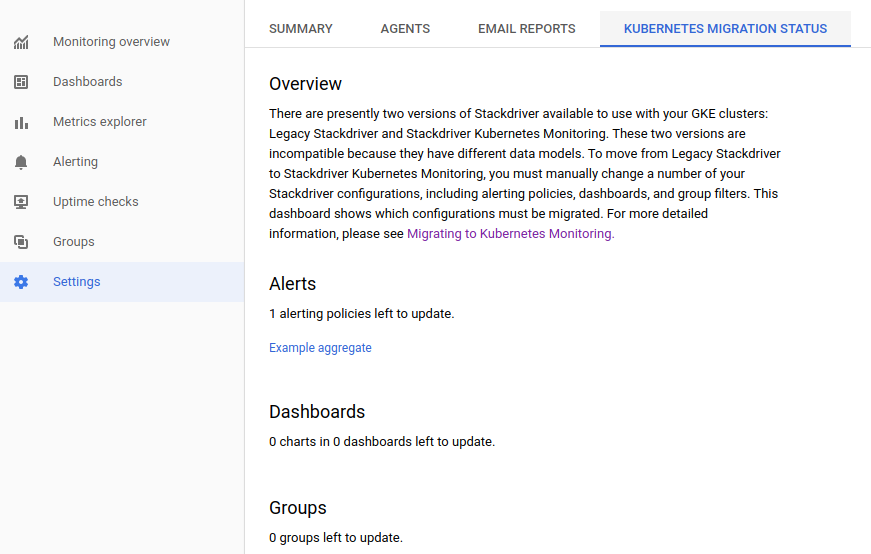
Ensure the migration status is the expected one
Open the monitoring site at the GCP GUI and then go to Settings. You will find a tab named “Kubernetes Migration Status” which should look as follows.
Fully enable the logging&monitoring service for your cluster
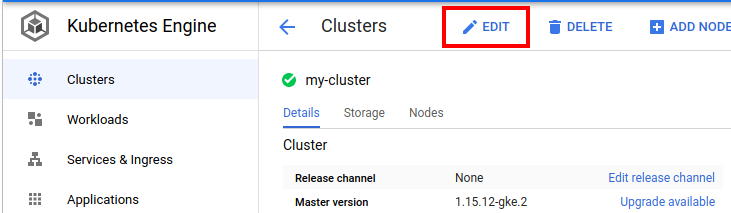
Open the GKE clusters list and then click on the name of the cluster where you want to setup the new logging system. Once you see the cluster config, click on the EDIT button as is shown below.
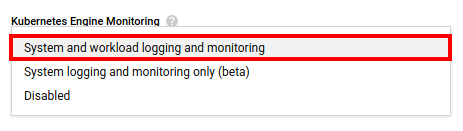
Scroll down until finding the Kubernetes Engine Monitoring setting and then select the System and workload logging and monitoring option.
IMPORTANT: Don’t forget to save your changes at the bottom.
And that’s it! Your cluster will receive logs again as expected!
Conclusion
As you may probably know Google Cloud Platform is still in beta, so you will often find some changes breaking your already-working systems. You have two options at this point: On the one hand you could keep yourself up to date with all the future changes and deprecations. On the other hand you could just limit yourself to fix them as soon as they appear, but keep in mind you will always be blindly fighting against them.
There is a third option (which should be the first one), consisting on regularly coming to the Geko’s blog and check out if we have already dealt with the problem you are encountering. The Geko team will be always glad to see you here 🙂