

Today we are going to talk about AWS recommendations to deploy WordPress in your cloud. AWS offers us a multitude of solutions depending on the environment we need to deploy. In most cases we will want to deploy this well-known CMS taking advantage of the solutions offered by AWS in terms of scalability and flexibility, and one of the many recommendations is to use Elastic File System (EFS) as a storage system. Referring to this point, we have a conference offered at the AWS Reinvent of 2017 by one of the AWS solution architects in which they make a small laboratory deploying WordPress in a scalable environment with high availability.
AWS re:Invent 2017: Learn to Build a Cloud-Scale WordPress Site That Can Keep Up wit (STG324)
After seeing what AWS tells us, we are clear that the scheme to deploy an “ideal” environment with WordPress in the cloud should be something like that.
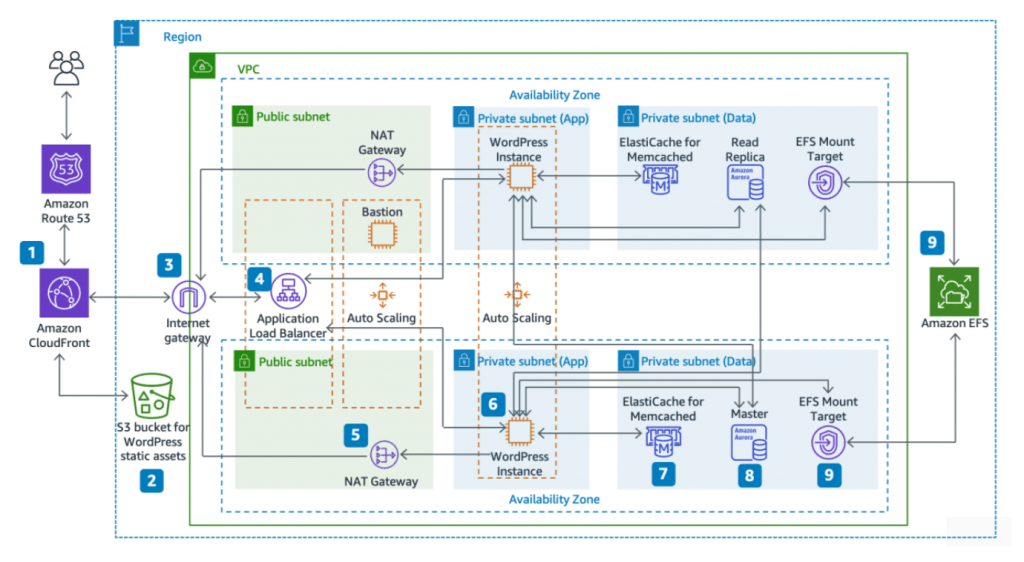
Now that we have understood this, let’s go to actual practice. We have to migrate a client from a non-cloud provider to AWS. This client has a simple, but quite bulky, environment since migration involves moving more than 50 wordpress to the same server and moving from a completely monolithic environment to a scalable, flexible and elastic environment to solve performance problems and try to offer a better service to its clients, as well as the ease of being able to grow the platform easily if necessary.
In a first phase, we decided to make a first migration on 5 websites. From this moment the problems begin.
For our part we define an architecture based on an autoscaling system with which, these instances will be the ones that execute the web code contained in an EFS volume shared with the availability zones where our instances are located.
Once deployed, we perform some performance tests and … bad signal, the time to first byte is more than 35 seconds. Ok, it could be our fault, so we are going to use Cloudfront as a cache and CDN in order to optimize loading times… We deployed Cloudfront distributions and got a “brutal” performance improvement, now the time to first byte is On average 30 seconds. Disappointing. Here we can see a table with the supposed performance of EFS:
| File System Size (GiB) | Baseline Aggregate Throughput (MiB/s) | Burst Aggregate Throughput (MiB/s) | Maximum Burst Duration (Min/Day) | % of Time File System Can Burst (Per Day) |
|---|---|---|---|---|
| 10 | 0.5 | 100 | 7.2 | 0.5% |
| 256 | 12.5 | 100 | 180 | 12.5% |
| 512 | 25.0 | 100 | 360 | 25.0% |
| 1024 | 50.0 | 100 | 720 | 50.0% |
| 1536 | 75.0 | 150 | 720 | 50.0% |
| 2048 | 100.0 | 200 | 720 | 50.0% |
| 3072 | 150.0 | 300 | 720 | 50.0% |
| 4096 | 200.0 | 400 | 720 | 50.0% |
After this, we decided to enable OPCache, so remember, we have WordPress running in several instances of an autoscaling group with OPCache and Cloudfront caching and with the code on an EFS shared volume. Now the time to first byte is about 20 seconds when the file is requested and is not in the cache.
At this point, we think that the problem is that EFS may need provisioning, which we did and did not improve anything … We were at a crossroads, since we had followed all the Amazon recommendations and we had not improved the client platform, but instead It had worsened. We analyzed the situation thoroughly and carried out an infinite number of tests to reach the conclusion that EFS is not efficient when working with many thousands of small files, because the speed of access or reading of these files is very small.
Finally, we decided to dispense with EFS and set up our own NFS server on EC2 using it the same way we used EFS. There the code of the wordpress was stored and this is served to the instances of autoscaling that is the one who executes them. Surprisingly with this change, the time to first byte has become less than 1 second.
In conclusion, and as a personal opinion, EFS might be useful in some contexts, in our particular case it has not offered us the performance we needed and we had to do without it. With this, we take the opportunity to comment that from Geko we analyze the needs of our customers from all possible points of view to offer the best solutions and those that best suit their needs.
If you have any suggestions or want to contact us you can do it through email [email protected].
We will be happy to hear from you. And don’t forget, Feel the Geko way!! 🙂