

Introduction
Practical tips to improve your developments in CDK
The new AWS infrastructure as code framework, CDK, it’s awakening interest in the DevOps world due to its multiple advantages. At Geko we are already using CDK and we can say that it is a very interesting alternative to both Cloudformation and Terraform. For those who want to introduce in the DevOps world or those companies that want to implement a DevOps model, CDK is the perfect tool since, it allows the use of programming languages already used by developers, reducing the learning curve and facilitating its adoption.
However, after using CDK in production we can say that adopting CDK is not as easy as it might appear. For this reason, we have created this post with the intention of explaining some basic concepts of CDK and at the same time sharing with you advices based on our experience, for all those who are considering starting to use CDK or those who are already using it and they want to improve its use.
Naming convention for identifiers
In CDK there are many types of identifiers and each one has a purpose. Our first recommendation is that you inform yourself about how identifiers work and the importance they have in order to create resources in cloudformation. Identifiers in CDKs must be unique within the context in which they are created. This has many notable implications.
For example, the same ID can be used for two constructs that are on two different stacks. However, if you try to use the same ID for two constructs on the same Stack, the application will return an error synthesizing or deploying in AWS. Our advice is to centralize, somehow, the generation of all identifiers, following the same nomenclature. This will help you to avoid repeat identifiers and it will make easier to read the cloudformation templates created with the CDK. You can use a helper function that, given a set of parameters, returns the identifier to be used in the constructs, as shown below.

Try to simplify the naming convention that you define for the identifiers as much as possible, since the logical and physical identifiers generated by CDK are usually very long and include hash codes that make them difficult to read. Always keep in mind that, once you have defined resource identifiers, you should not change them unless it is completely and absolutely necessary. Once you have deployed a resource with an identifier, if the identifier changes, the resource will be replaced with a new one. Imagine you’ve created an RDS instance in production and assigned an ID to it. If you change the RDS instance identifier in your CDK code, the next time you deploy to production the RDS instance will be removed and replaced with a new one. An RDS instance is created in the following CDK code snippet:

By deploying this code, an RDS instance will automatically deployed in a cloudormation stack:
This RDS instance has been created with the identifier Pro-Geko-Cloud-RDS, the values defined for the environment and project attributes are the following:

The cloudformation template generated by CDK is as follows:

The logical name of the RDS instance is ProGekoCloudRDS and a concatenated hash identifier as suffix. We will now modify the static get_identifier method to add the dpt attribute, as shown below:
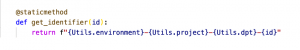
We also set a value for the static attribute department:

If we execute a cdk diff command we can see that there are pending changes. Changes include replacing the RDS instance with a new instance called ProGekoCloudsalesRDS:
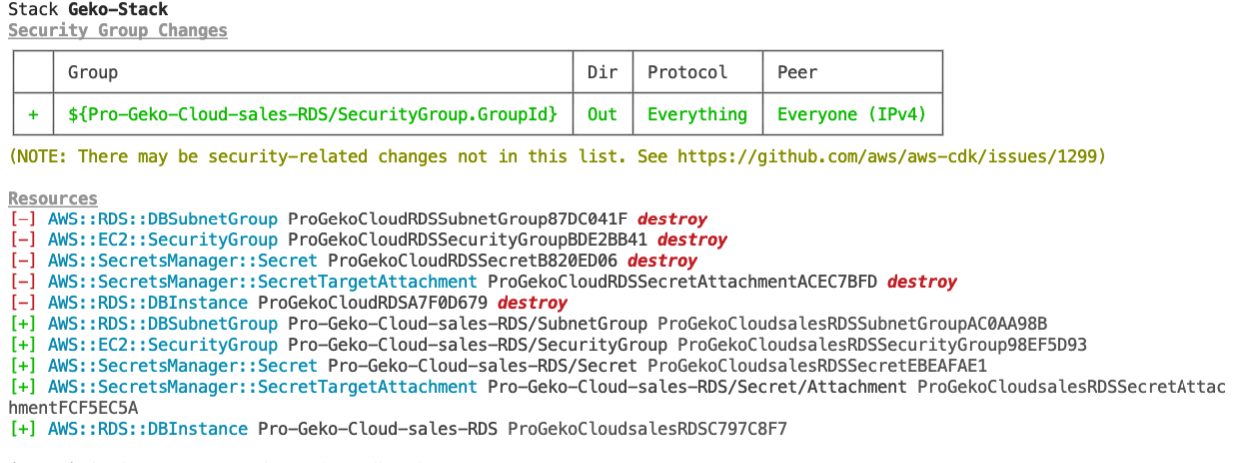
As we have seen, identifiers are vital for a CDK application. Before you start generating source code, define a naming convention and follow it. One way to avoid unwanted identifier changes is to run the CDK diff command in your deploy pipeline, prior to deploying your infrastructure.
Finally, try not to define names for any resource you provision in your application, let the CDK choose the names of the resources. Keep in mind that I’m talking about resource names, not identifiers. Every time you make changes in a cloudformation resource, it is possible that resource will be replaced due to the changes you want to make are not compatible with the update of the resource. then, it is possible the update fails due to you defined a name for a resource that has to be replaced. AWS CloudFormation doesn’t replace a resource that has a custom name unless that custom name is changed to a different name. If you allow CDK to handle resource naming, in case you make any changes that involve replacing a resource, CDK automatically replaces the resource and assigns it a new name, avoiding errors.
Tagging
Adding tags to AWS resources is a must. The advantages of using tags are many and there aren’t drawbacks. Adding tags in CDK is very easy, as shown in the following image:

Regarding which tags to use, it depends on several factors, however, the tag Name is essential especially because, as we have seen in the previous section, identifiers that CDK assigns to resources are unintelligible. Adding a tag Name to all resources makes it much easier to easily identify resources. We could also use the Owner tag in order to identify which department owns the infrastructure. The Project tag is a classic example, it is usually used to identify which resources belong to a project. In any case, even if you don’t agree with the recommended tags, you should define a tagging policy aligned with the compliance of your company because it will greatly facilitate the management of your infrastructure, either to locate resources or to identify costs.
Testing
Testing your application is always a best practice and good advice to follow. It helps us find bugs more easily, deliver higher quality software, and it can even help us develop faster if we use development methodologies like TDD. In CDK there are two types of tests that we are going to see.
On the one hand, there are fine-grained tests, that are very similar to unit tests. In a fine-grained test you can perform various checks. For instance, you can check that your application is creating a certain type of resource, for example an RDS instance. You can also verify the properties of your resources. For example, it’s possible to verify that the RDS instance that we have seen in the identifiers section are using MySQL version 8.0.16 as database engine:

To implement test in CDK you will need to import the assertions module. If you use Python you can use Pytest to implement your tests.
On the other hand are the snapshot tests. These tests are used when you want to refactor the code of your CDK application. Use snapshot tests to check you don’t introduce changes when refactoring your applications. In order to run snapshot tests in Python, you have to install the Syrupy python library. Once installed you can start creating your snapshot tests:

This test has two parameters, the first one is the CDK environment and the second one is the snapshot parameter that represents the cloudformation template used as a reference to execute the snapshot test. Snapshot parameter is managed by the Syrupy library, you just have to define it. The test creates the stack to check in the first place. It obtains the cloudformation template of the stack and compares it with the snapshot parameter. If the template doesn’t match with the snapshot parameter, the test fails. When executing a snapshot type test for the first time, you must define the –snapshot-update flag, like this:

When you run this command, Syrupy library will create a folder called __snapshots__ in your tests folder.

The cloudformation template generated by the CdkGekoStack stack will be saved in __snapshot__ folder. The next time you want to run the snapshot type test, you have to run the python -m pytest command without the –snapshot-update flag. If the CdkGekoStack stack returns a template that doesn’t match with the template that Syrupy has already saved in the __snapshot__ folder, the test will fail.
Resume
In this post we have talked about naming convention, tagging and testing. Concepts as basic as important. We promise that in the next post, we are going to talk about more complex concepts such as property management and constructs. So far, we say goodbye. See you!
If you require any further information, feel free to contact us.