

ElasticSearch service has become one of the preferred services where sysops department store logs and metrics information.
Recently, we faced with a problem that we already solved related with the user_agent field we get from nginx json logs.
When a new request transaction goes to our web services we want to get some certain relevant information about the agent who is trying to get that information.
Example:
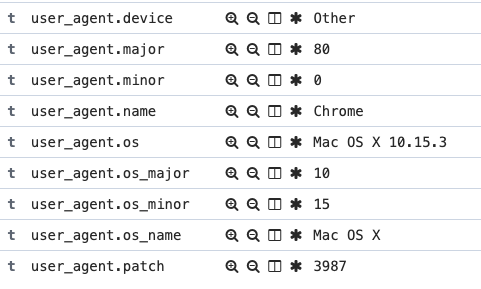
In the past, elastic search comes with an specific plugin that generate those fields with all the agent information. And even the AWS elasticsearch services has come with this plugin.
Usefull links:
https://docs.amazonaws.cn/en_us/elasticsearch-service/latest/developerguide/aes-supported-plugins.html
https://www.elastic.co/guide/en/elasticsearch/plugins/master/ingest-user-agent.html
But now, the plugin has been replaced by a specific processor inside Elasticsearch engine.
Then, how we can make it work with the logs ingest?
The quickest answer is just using a pipeline that calls our user agent processor inside the ingest controller using the next schema:
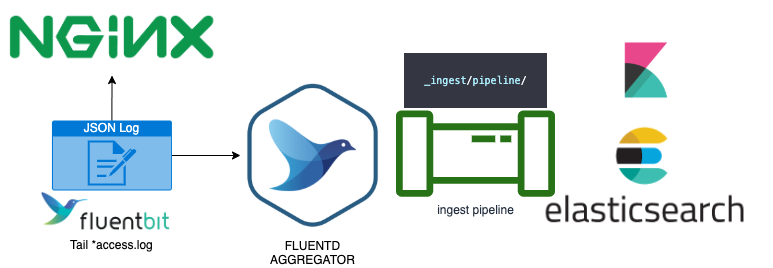
In our case, we use fluentbit inside our customer web servers to collect the json file that nginx generates and then all the agents send that info by streaming to a fluentd agrgregator service where we had configured the OUTPUT plugins of several databases and storage collectors. In our case, elasticsearch.
Inside the Elasticsearch we create a new pipeline and just need to tell the name of the user agent field we get from json:
PUT _ingest/pipeline/nginx { "description" : "Add user agent info from nginx user agent", "processors" : [ { "user_agent" : { "field" : "nginx-agent-field" } } ] }
So now we have created the pipeline telling the field name of our nginx user agent. Now how we connect pipeline with the logs ingest from aggregator?
Easy, we just need to specify the pipeline ingest inside our tdagent configuration in the match rule like this
/etc/td-agent/td-agent.conf:
@type "elasticsearch" host elasticsearchtest.eu-west-1.es.amazonaws.com port 443 scheme https ssl_verify true ssl_version TLSv1_2 type_name "access_log" logstash_prefix "nginx" logstash_format true include_tag_key true pipeline nginx tag_key "@log_name" flush_interval 10s chunk_limit_size 4MB total_limit_size 512MB flush_interval 30s flush_thread_count 2 queue_limit_length 15 retry_max_interval 30 retry_forever true
As you can see we configure the ingest using pipeline attribute with the pipeline name we already created before, in our case nginx:
pipeline nginx
Just adding the pipeline with the user agent processor, now our ingest will add for every row in our elasticsearch database the user agent information in the fly.
Advice!: After few weeks of test in real production environment with the pipeline method, we can say that this processor needs too much CPU to process in real time and build the transformations. So we decided to configure a filter inside fluentd to use ua plugin in aggregator layer and it works much better now!
#td-agent-gem install fluent-plugin-ua-parser
Hope it helps! Contact us if you have any questions! 😉