

El servicio ElasticSearch se ha convertido en uno de los servicios preferidos en los que los sysops almacenan registros e información de métricas.
Recientemente, nos enfrentamos a un problema que ya resolvimos relacionado con el campo user_agent que obtenemos de los registros nginx json.
Cuando una nueva request transaction va a nuestros servicios web, queremos obtener cierta información relevante sobre el agente que está tratando de obtener esa información.
Ejemplo:
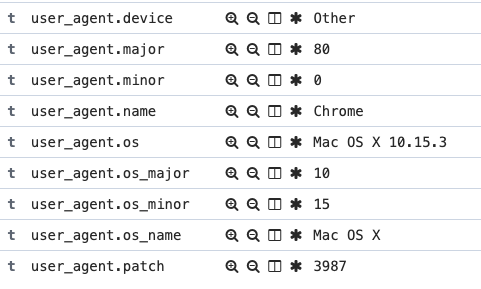
En el pasado, elastic search venía con un plugin específico que genera esos campos con toda la información del agente. E incluso los servicios de ElasticSearch de AWS vienen con este plugin.
Enlaces útiles:
https://www.elastic.co/guide/en/elasticsearch/plugins/master/ingest-user-agent.html
Pero ahora, ese plugin ha sido reemplazado por un procesador específico dentro del procesador Elasticsearch.
Then, how we can make it work with the logs ingest? Entonces, ¿cómo podemos hacer que funcione con los logs ingest?
La respuesta más rápida es simplemente usar una pipeline que llama a nuestrouser agent processor dentro del ingest controller usando el siguiente esquema:
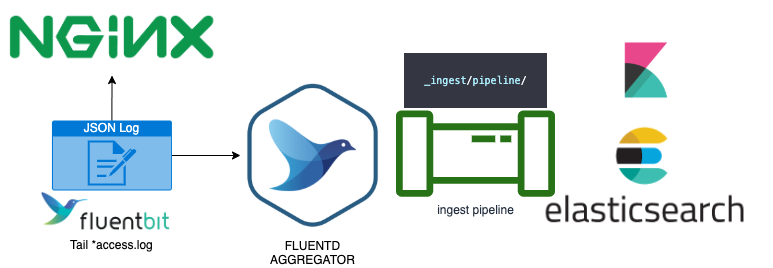
En nuestro caso, usamos fluentbit dentro de los servidores web de nuestros clientes para recopilar el archivo json que genera nginx y luego todos los agentes envían esa información mediante un servicio fluentd agrgregator donde habíamos configurado los OUTPUT plugins de varias bases de datos y recopiladores de almacenamiento. En nuestro caso, elasticsearch.
Dentro de Elasticsearch creamos una nueva pipeline y solo necesitamos indicar el nombre del campo user_agent que obtenemos de json:
PUT _ingest/pipeline/nginx { "description" : "Add user agent info from nginx user agent", "processors" : [ { "user_agent" : { "field" : "nginx-agent-field" } } ] }
Así que ahora hemos creado la pipeline que indica el nombre del campo nginx user agent. Ahora, ¿cómo conectamos la pipeline con el log ingest del agregador?
Fácil, solo necesitamos especificar la pipeline ingest dentro de nuestra configuración tdagent en una match rule como esta
/etc/td-agent/td-agent.conf:
@type "elasticsearch" host elasticsearchtest.eu-west-1.es.amazonaws.com port 443 scheme https ssl_verify true ssl_version TLSv1_2 type_name "access_log" logstash_prefix "nginx" logstash_format true include_tag_key true pipeline nginx tag_key "@log_name" flush_interval 10s chunk_limit_size 4MB total_limit_size 512MB flush_interval 30s flush_thread_count 2 queue_limit_length 15 retry_max_interval 30 retry_forever true
Como puedes ver, configuramos el ingest utilizando el pipeline attribute con el pipeline name que ya creamos anteriormente, en nuestro caso nginx:
pipeline nginx
Simplemente agregando la pipeline con el user agent processor, ahora nuestra ingest agregará para cada fila en nuestra base de datos de Elasticsearch la información del user_agent sobre la marcha.
¡Consejo!: Después de algunas semanas de prueba en un entorno de producción real con el método de pipelines, podemos decir que este procesador necesita demasiada CPU para procesar en tiempo real y construir las transformaciones. ¡Así que decidimos configurar un filtro dentro de fluentd para usar el plugin ua en la aggregator layer y ahora funciona mucho mejor!
#td-agent-gem install fluent-plugin-ua-parser
¡Espero que os ayude! ¡Contáctanos si tienes dudas! 😉