

We want to share with you a problem that we have recently solved with a project.
RDS is the managed database service offered by AWS that solves the main management, operation and maintenance problems involved in having a relational database platform. With RDS everything is very simple, you guarantee the service and the operative allowing to grow and to decrease according to necessity.
In addition Amazon has its own engine based on Mysql, Aurora that even allows to have a serverless database platform! Which we will talk about in another post later.
The scenario we face
A client with its full AWS-based platform with all its relational databases using RDS manifests in one of its platforms performance problems, crashes, wandering and unpredictable behavior etc.
It turns out that this problem does not occur from the beginning but at a certain point in time it started to degrade until it became a real problem. We appreciate that RDS was deployed using T3 bursting instance where credits seemed to decrease periodically.
We decided to change the instance to type M5 to have a better performance and resource availability . The performance improves very significantly until we noticed the following:
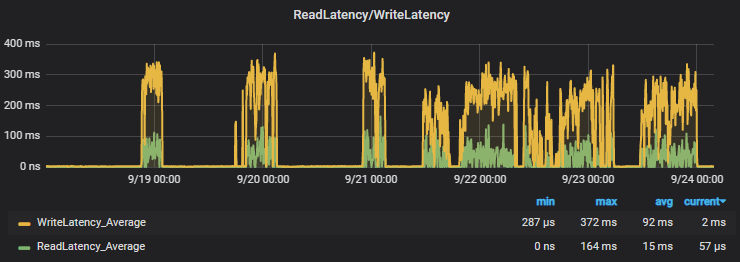
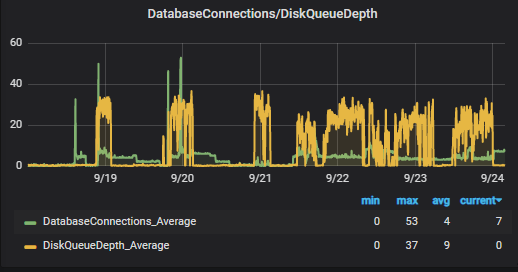
The metrics continue to warn that there is write/read latency and IOPS are glued. How is this possible in a general purpose SSD?
The metric that for us is important to follow in any RDS is the one referring to the Disk QueueDepth, this metric indicates the size of the queue that the system has waiting to be processed in disk IO operation, that is, the debt in disk operations that the system has. Read Write disk latencies are nothing more than mirages of this fact.
The solution
The explanation is simple, AWS RDS provides a total of 3 IOPS/Gb depending on the size of the EBS disk that is created. The client RDS was created with 20Gb total size = 60 IOPS , which AWS by default always provides a minimum of 100 IOPS.
This explained why the CPU and RAM were not affected but the performance as such was.
As we detected the bottleneck, we simply proceeded to expand via Terraform the size of the associated EBS volume to 100Gb with its corresponding 300IOPS (three times as before).
The result here you have it :
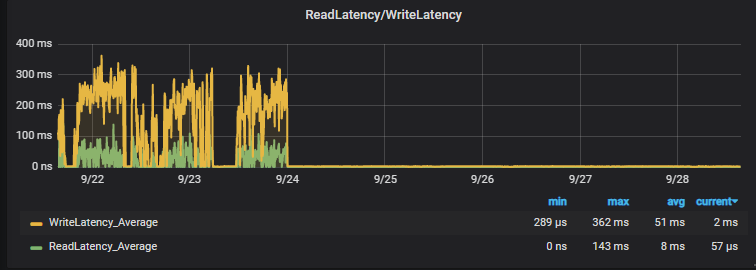
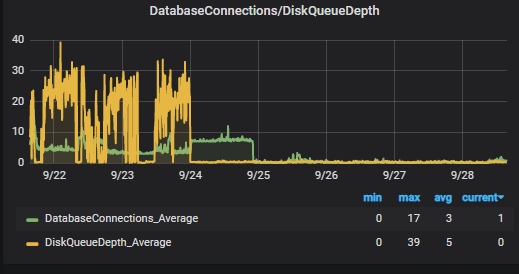
Nothing more to add, no more latencies, no more blockages and no more problems with this platform, we leave you the link to the official AWS documentation on RDS and EBS
Remember that for productive environments, the recommendation is always to provide at least 100Gb per disk (even if we don’t need it) to obtain those 300 IOPS minimum.
Remember that at Geko we are still at your disposal to help you with any performance problems you may have with your platform.