

Sí, puedes pensar: «¿Qué? Google Cloud tiene su propio servicio administrado de balanceador de carga. ¿Por qué querría configurar y administrar un load balancer HA dedicado?«. Recomendamos utilizar el servicio GCP Load Balancer siempre que puedas. Es un servicio muy confiable y no tienes que administrar tu propio load balancer en una configuración de alta disponibilidad.
Pero a veces hay algunas situaciones en las que GCP Load Balancer no se ajusta a tus necesidades o, simplemente, no deseas usarlo … En esos casos, tenemos una configuración muy simple utilizando dos piezas de software bien conocidas: HAProxy y Keepalived.
Keepalived utiliza Virtual Router Redundancy Protocol (VRRP) y direcciones IP flotantes que pueden ‘moverse’ de una VM a otra en caso de que una de ellas no esté disponible. En un entorno clásico y local, esto es algo así:

En caso de un server failure, cuando el otro servidor toma las direcciones IP flotantes, agrega estas direcciones a tu interfaz de red. El servidor anuncia esta toma de control a otros dispositivos que utilizan la layer 2 mediante el envío de un marco de Protocolo de resolución de direcciones (ARP) gratuito. Google Compute Engine utiliza virtualized network stack y los mecanismos de implementación típicos no funcionan aquí. La red VPC maneja las solicitudes ARP basadas en la topología de enrutamiento configurada e ignora las tramas ARP gratuitas.
En primer lugar, debes instalar haproxy y keepalived en tu servidor. En este caso, usamos Ubuntu 18.04. Solo ejecuta:
sudo apt install haproxy sudo apt install keepalived
Para este tutorial configuraremos un load balancer interno, pero también puedes configurar un load balancer externo con algunas pequeñas modificaciones.
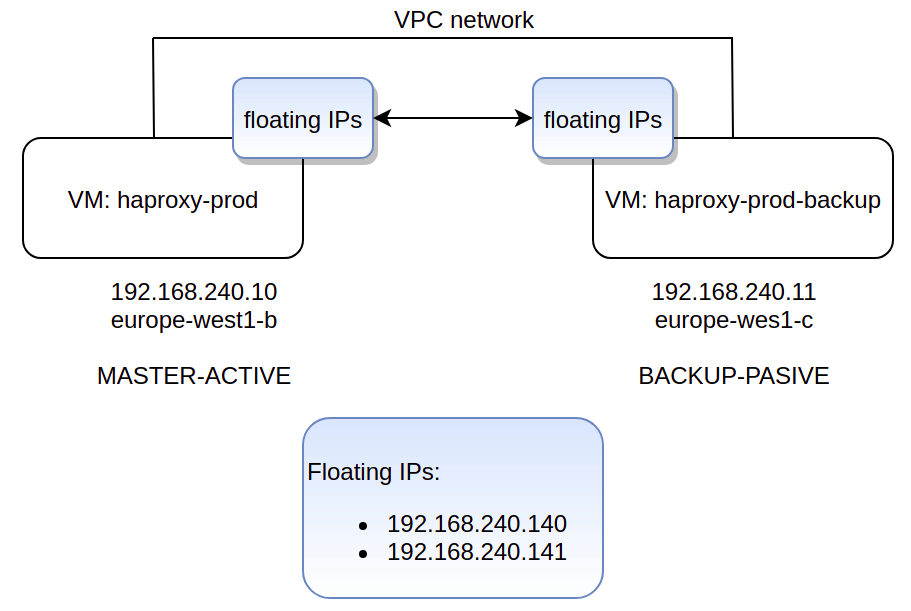
Utilizaremos este archivo /etc/haproxy/haproxy.cfg en ambos servidores. Ambos servidores (MASTER y BACKUP) deben tener exactamente la misma configuración de HAProxy.
global log /dev/log local0 debug log /dev/log local1 debug chroot /var/lib/haproxy stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners stats timeout 30s user haproxy group haproxy daemon defaults log global mode http option dontlognull timeout connect 5000 timeout client 50000 timeout server 50000 errorfile 400 /etc/haproxy/errors/400.http errorfile 403 /etc/haproxy/errors/403.http errorfile 408 /etc/haproxy/errors/408.http errorfile 500 /etc/haproxy/errors/500.http errorfile 502 /etc/haproxy/errors/502.http errorfile 503 /etc/haproxy/errors/503.http errorfile 504 /etc/haproxy/errors/504.http frontend service-1 bind 192.168.240.140:443 mode tcp option tcplog log global default_backend service-1-be backend service-1-be mode tcp server service-1-server-1 10.152.0.220:443 check id 1 server service-1-server-2 10.152.0.221:443 check id 2 frontend service-2 bind 192.168.240.141:443 mode tcp option tcplog log global default_backend service-2-be backend service-2-be mode tcp server service-2-server-1 10.10.0.40:443 check id 1 server service-2-server-2 10.10.0.41:443 check id 2
En este ejemplo, las dos IP flotantes serán: 192.168.240.140 y 192.168.240.141.
No olvides reiniciar el servicio haproxy (sudo systemctl restart haproxy) cada vez que cambies el archivo de configuración. 😉
Para el archivo de configuración /etc/keepalived/keepalived.conf usaremos estos dos archivos de configuración en las VM masters y slaves:
MASTER
vrrp_instance floating_ip { state MASTER interface ens4 unicast_src_ip 192.168.240.10 unicast_peer { 192.168.240.11 } virtual_router_id 50 priority 100 authentication { auth_type PASS auth_pass your_passwd } notify_master /etc/keepalived/takeover.sh root }
BACKUP
vrrp_instance floating_ip {
state BACKUP
interface ens4
unicast_src_ip 192.168.240.11
unicast_peer {
192.168.240.10
}
virtual_router_id 50
priority 50
authentication {
auth_type PASS
auth_pass your_passwd
}
notify_master /etc/keepalived/takeover.sh root
}
No olvides reiniciar el servicio keepalived (sudo systemctl restart keepalived) cada vez que cambie el archivo de configuración. 😉
Y ahora la parte que hace la ‘magia’: el script /etc/keepalived/takeover.sh. Básicamente, este script desasigna los alias de IP del par que está inactivo y se los asigna a sí mismo. Después de eso, el servicio haproxy se vuelve a cargar para permitir que el haproxy se una a las IP flotantes.
MASTER
# Unassign peer's IP aliases. Try it until it's possible. until gcloud compute instances network-interfaces update haproxy-prod-backup --zone europe-west1-c --aliases "" > /etc/keepalived/takeover.log 2>&1; do echo "Instance not accessible during takeover. Retrying in 5 seconds..." sleep 5 done # Assign IP aliases to me because now I am the MASTER! gcloud compute instances network-interfaces update haproxy-prod --zone europe-west1-b --aliases "192.168.240.140/32;192.168.240.141/32" >> /etc/keepalived/takeover.log 2>&1 systemctl restart haproxy echo "I became the MASTER at: $(date)" >> /etc/keepalived/takeover.log
BACKUP
# Unassign peer's IP aliases. Try it until it's possible. until gcloud compute instances network-interfaces update haproxy-prod --zone europe-west1-b --aliases "" > /etc/keepalived/takeover.log 2>&1; do echo "Instance not accessible during takeover. Retrying in 5 seconds..." sleep 5 done # Assign IP aliases to me because now I am the MASTER! gcloud compute instances network-interfaces update haproxy-prod-backup --zone europe-west1-c --aliases "192.168.240.140/32;192.168.240.141/32" >> /etc/keepalived/takeover.log 2>&1 systemctl restart haproxy echo "I became the MASTER at: $(date)" >> /etc/keepalived/takeover.log
De hecho, todo lo que hacemos es asignar / desasignar alias de IP dependiendo de qué VM sea el MAESTRO.
Fácil, ¿no? 🙂
Espero que hayas disfrutado de este post y te animo a que revises nuestro blog para leer otrosposts que puedan ser de tu interés, por ejemplo «Qué es el cloud?«.
Si tienes alguna duda, contáctanos and Feel the Geko Way!