

Por qué hablamos de MLOps
DevOps resolvió cómo pasar código a producción con calidad y velocidad. Pero en machine learning no solo cambia el código: cambian los datos y, cuando cambian los datos, cambian las predicciones.
Ahí aparece MLOps, que aplica disciplina y automatización a todo el ciclo de datos + features + modelos para que el ML funcione de verdad en producción.
DevOps son las prácticas para que desarrollo y operaciones entreguen software de forma continua, con automatización (CI/CD), pruebas y observabilidad.
MLOps lleva esas ideas al machine learning. Además del código, gestiona datos, experimentos y modelos, con piezas como registro de modelos, entrenamiento continuo y monitorización del modelo y de los datos en producción.
En qué se parecen y en qué difieren
Ambas disciplinas buscan estabilidad y rapidez, pero MLOps añade piezas porque el modelo depende de datos que cambian con el tiempo.
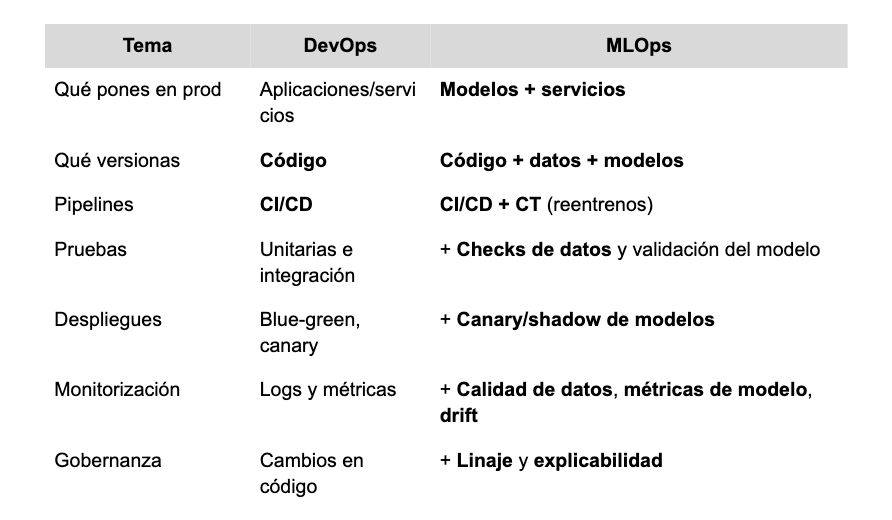
La idea clave es que DevOps hace fiable el código hoy y MLOps mantiene fiable código + datos + modelo a lo largo del tiempo.
Cómo MLOps está cambiando el sector gracias a la IA
La IA se ha metido en productos y procesos de negocio. MLOps es el puente que lo hace posible a escala. Lleva modelos a producción, los mantiene sanos y convierte datos en valor continuo:
- De proyectos a productos vivos
Antes había pilotos que morían tras la demo. Ahora hay modelos con ciclos de vida claros, SLOs y runbooks, que se actualizan solos (CT) cuando cambian los datos. - Time-to-value mucho menor
Pipelines y “plantillas” reducen meses a semanas. Los equipos lanzan canaries rápidos, miden impacto online y promueven modelos con evidencia, no con intuición. - Datos como activo de producto
Con feature stores, linaje y tests de calidad, las features se comparten entre equipos. Resultado: menos duplicidad, menos bugs y aprendizaje cruzado real. - Coste y rendimiento bajo control
MLOps añade autoscaling, elección batch/tiempo real y métricas de coste por predicción y coste de reentrenar. La IA deja de ser “caja negra cara” y pasa a ser predecible. - Observabilidad de modelos (no solo de apps)
Además de logs y latencia, se vigilan calidad de datos, drift y métricas del modelo (F1, AUC, MAE). Cuando el modelo se degrada, salta una alerta y se activa el reentrenamiento. - Gobernanza y confianza
Linaje, explicabilidad y auditoría permiten cumplir normativas y políticas internas. Decisiones sensibles (crédito, salud, precios) se explican y trazan. - LLMOps: IA generativa con reglas
Para GPT-like/LLMs, MLOps evoluciona: versionado de prompts, evaluación automática (calidad factual/toxicidad), RAG con control de fuentes y métricas de tokens, latencia y coste. Menos alucinaciones, más robustez. - Casos con impacto directo (ejemplos típicos)
Predicción de demanda y precios dinámicos, detección de fraude en tiempo real, mantenimiento predictivo, búsqueda/soporte con IA generativa, recomendadores y next-best-action.
Qué cambia en la práctica con MLOps
- De “experimento” a “producto”: un owner, SLOs y métricas online.
- Plantillas y pipelines: ingesta → features → entrenamiento → evaluación → despliegue → monitorización.
- Medir y aprender: dashboards de negocio + modelo; reentrenos automáticos con aprobación.
- Seguridad/ética integradas: control de accesos, privacidad, explicabilidad y sesgos monitorizados.
La IA crea valor cuando se opera. MLOps es esa operación: convierte modelos en capacidad repetible, con costes y riesgos controlados.
Componentes principales de MLOps
Este es el “kit” básico. No necesitas todo desde el día uno, pero conocer cada pieza te ahorra problemas después.
1. Ingesta y calidad de datos
Este bloque trae los datos desde sus fuentes y comprueba que tengan formato, rangos y reglas correctas. Si entran columnas nuevas o valores extraños, el modelo puede fallar sin avisar; por eso los tests de datos son tan importantes como los tests de código.
2. Feature engineering y feature store
Las features son las variables que usan los modelos. Un feature store guarda su definición y versiones para entrenamiento y producción. Así evitas el clásico error de “calcular una cosa en el notebook y otra diferente en el servicio”.
3. Seguimiento de experimentos (experiment tracking)
Cada entrenamiento produce métricas y artefactos. Registrar hiperparámetros, datasets y resultados permite comparar, repetir y justificar por qué elegiste “el modelo B” y no “el A”.
4. Registro de modelos (model registry)
Es el catálogo donde viven los modelos con sus versiones y estados (dev, staging, prod). Facilita promociones controladas, rollback rápido y auditoría de qué versión generó cada predicción.
5. Orquestación de pipelines
Automatiza la cadena datos → features → entrenamiento → evaluación → registro → despliegue. Un orquestador convierte pasos manuales en un proceso repetible, con reintentos y visibilidad de cada tarea.
6. CI/CD/CT
- CI comprueba el código y también puede validar esquemas de datos.
- CD despliega servicios y modelos con seguridad (blue-green/canary).
- CT reentrena cuando toca: por calendario o porque la calidad online cayó por debajo de un umbral.
7. Serving: cómo sirves predicciones
Hay tres modos principales: batch (jobs programados), tiempo real (API con autoscaling) y streaming (eventos). Lo crítico es mantener paridad de features entre entrenamiento y producción para no degradar el modelo por diferencias de cálculo.
8. Evaluación offline y online
Primero validas offline con conjuntos de prueba y checks de sesgo. Luego mides online con A/B o canary: así confirmas que el modelo nuevo mejora de verdad en tu entorno real.
9. Monitorización de modelo, datos y sistema
Además de logs y latencia, vigila calidad de datos, drift (cuando cambian las distribuciones) y métricas del modelo como precisión o MAE. Define umbrales y alertas con planes de acción para reaccionar a tiempo.
10. Gobernanza y cumplimiento
Incluye linaje (qué datos y qué versión de modelo generaron una predicción), explicabilidad para decisiones sensibles y controles de seguridad y privacidad. Esto no es adorno: reduce riesgos legales y operativos.
El ciclo de vida de un sistema de ML
Ver el proceso completo ayuda a priorizar. El flujo típico es el siguiente:
- Define el objetivo de negocio y las métricas que importan.
- Ingiere y valida los datos de entrada.
- Crea y versiona features en un feature store.
- Entrena y registra tus experimentos con sus resultados.
- Promueve el mejor modelo en el registry.
- Despliega con canary o shadow para reducir riesgos.
- Monitoriza datos, modelo y sistema con alertas.
- Reentrena (CT) si la calidad cae o llegan datos nuevos relevantes.
Arquitectura de referencia
Piensa en capas para no mezclar responsabilidades:
- Una capa de datos con calidad y catálogo.
- Una capa de features común para train y serve.
- Pipelines orquestados.
- Tracking/registry para saber qué funciona.
- Serving en batch o tiempo real.
- Observabilidad que ve app + modelo + datos.
- Gobernanza para auditar y explicar.
Herramientas por categoría
No se trata de tener “la herramienta de moda”, sino de cubrir bien cada categoría y que todo integre fácil:
- Tracking/registry: MLflow, Weights & Biases, registries gestionados en nube.
- Orquestación: Airflow, Prefect, Dagster, Kubeflow.
- Feature store: Feast u opciones cloud (Vertex/Databricks/Tecton).
- Serving: KServe/Seldon, BentoML o endpoints gestionados.
- Monitoring de ML: Evidently, Arize, Fiddler, WhyLabs.
- Data quality: Great Expectations, Deequ.
- Base DevOps: Git, CI/CD (GitHub/GitLab/Jenkins), contenedores, Kubernetes y observabilidad clásica.
Métricas relevantes
Medir es lo que convierte un proyecto bonito en un sistema fiable. Sigue time-to-value (idea → primer canary), calidad online vs offline, tasa de drift y tiempo de reacción, coste por predicción y por reentrenamiento, además de SLOs (latencia, disponibilidad) y auditabilidad de predicciones.
Errores comunes y cómo evitarlos
- Todo en un notebook → añade tracking + registry + CI desde el inicio.
- Features distintas en train/serve → usa feature store y tests de paridad.
- Desplegar sin monitorizar → define métricas online y alertas obligatorias.
- Reentrenos sin control → aplica CT con aprobaciones y rollback.
- Lock-in prematuro → usa patrones portables y un plan de salida.
Ejemplo práctico
Supón que detectas fraude en pagos: entrenas con 12 meses de datos, registras experimentos y promueves el mejor modelo. Despliegas una API con canary al 10% y monitorizas precision/recall, latencia y drift en variables clave (importe, país, dispositivo).
Si la calidad baja, el CT reentrena con los últimos 30 días, valida offline, promueve a staging y vuelve a canary. Todo queda trazado con linaje, para saber qué datos y qué modelo generaron cada decisión.
Glosario rápido
- CT (Continuous Training): reentrenar modelos de forma automática y controlada.
- Drift: cambio en los datos o en su relación con la etiqueta que degrada el modelo.
- Model registry: catálogo de versiones de modelos con estados y metadatos.
- Feature store: capa común para definir, versionar y servir features coherentes.
- Canary/shadow: probar un modelo nuevo con poco tráfico o en paralelo, reduciendo riesgos.
La gran diferencia es simple
DevOps asegura el software; MLOps asegura el software + el modelo + los datos mientras todo cambia.
Empieza por cubrir lo básico (tracking, registry, CI/CD, monitorización y paridad de features) y ve sumando piezas cuando el valor ya sea visible. Así pasas de prototipos brillantes a impacto sostenido en producción.
¿Quieres saber más? Contacta con nuestro equipo de expertos.