

Elasticsearch es una herramienta que permite indexar muchos tipos de contenidos, como por ejemplo los logs de las aplicaciones, y en este artículo precisamente trataremos cómo indexar los logs HTTP de un loadbalancer y proxy como HAProxy, en el caso de querer registrar también los campos de User-Agent, X-Forwarded-For y Referrer, que por defecto no se muestran en los logs.
Actualmente en el mercado hay muchas herramientas disponibles para reenviar dichos logs a Elasticsearch, y en este caso usaremos Filebeat por ser una herramienta sencilla de instalar y configurar, y que cumple perfectamente con su cometido. Además es interesante mencionar que ha sido desarrollada por la misma empresa de Elasticsearch.
Pese a que Filebeat tiene ya un módulo para HAProxy que permite enviar e indexar sus logs en el formato que trae de forma predeterminada, en el caso de que queramos añadir más campos a dichos logs o sencillamente cambiemos su formato, tendremos que cambiar la forma en que Elasticsearch debe hacer la ingesta de datos.
Añadir más información en los logs de HAProxy
Supongamos que queremos que los logs de las peticiones HTTP muestren también otros campos como el User-Agent, X-Forwarded-For y Referrer, campos que van muy bien tener a tu disposición cuando se quiere monitorizar un sitio web y sin embargo no se guardan en los logs a no ser que lo especifiquemos de forma explicita. Para ello basta con añadir las siguientes líneas en las secciones frontend del archivo de configuración de HAProxy.
capture request header X-Forwarded-For len 15 capture request header User-Agent len 128 capture request header Referer len 128
Dado que HAProxy almacena por defecto en los logs las cabeceras de las peticiones HTTP que se han indicado capturar, no sería necesarío hacer nada más salvo reiniciar el servicio para aplicar los cambios y comprobar que efectivamente dichos campos se están mostrando en los logs.
Instalación Filebeat
La instalación y configuración del agente de Filebeat es muy sencilla, basta con seguir las instrucciones de la documentación oficial. Consiste en los siguientes pasos:
- Instalación del agente en función del sistema operativo
- Configuración de la información de conexión a Elasticsearch / Kibana.
- Activación del módulo para HAProxy.
- Carga a Elasticsearch de los recursos recomendados, como los index template y algunos paneles para Kibana.
La primera vez que el modulo conecte a Elasticsearch creara una ingest pipeline, que es el elemento que se encarga de parsear los logs.
Modificación de la Ingest Pipeline
A estas alturas ya deberíamos estar recibiendo los logs en Elasticsearch, pero los campos User-Agent, X-Forwarded-For y Referrer continuarían sin ser visibles pese a estar disponibles en los logs del HAProxy. Esto es debido a que la ingest pipeline creada por el módulo de Filebeat no tiene en cuenta dichos campos, y por tanto deberemos editarla.
Debemos editar los patrones del procesador Grok. Al hacer clic sobre el procesador para editarlo, deberíamos ver los siguientes patrones.
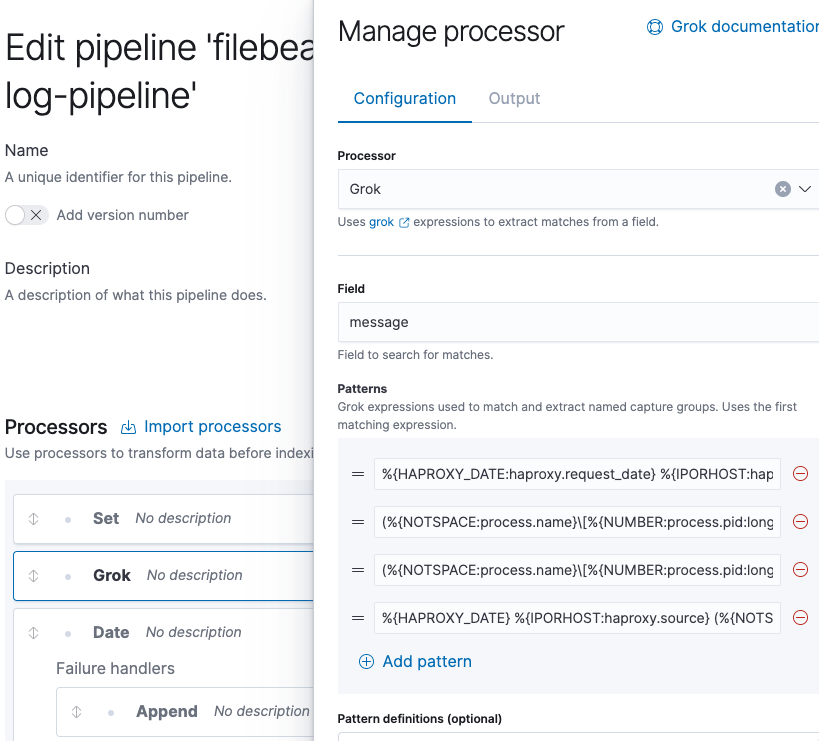
Debemos añadir uno nuevo con el siguiente contenido y moverlo a la segunda posición.
(%{NOTSPACE:process.name}[%{NUMBER:process.pid:long}]: )?%{IP:source.address}:%{NUMBER:source.port:long} [%{NOTSPACE:haproxy.request_date}] %{NOTSPACE:haproxy.frontend_name} %{NOTSPACE:haproxy.backend_name}/%{NOTSPACE:haproxy.server_name} %{NUMBER:haproxy.http.request.time_wait_ms:long}/%{NUMBER:haproxy.total_waiting_time_ms:long}/%{NUMBER:haproxy.connection_wait_time_ms:long}/%{NUMBER:haproxy.http.request.time_wait_without_data_ms:long}/%{NUMBER:temp.duration:long} %{NUMBER:http.response.status_code:long} %{NUMBER:haproxy.bytes_read:long} %{NOTSPACE:haproxy.http.request.captured_cookie} %{NOTSPACE:haproxy.http.response.captured_cookie} %{NOTSPACE:haproxy.termination_state} %{NUMBER:haproxy.connections.active:long}/%{NUMBER:haproxy.connections.frontend:long}/%{NUMBER:haproxy.connections.backend:long}/%{NUMBER:haproxy.connections.server:long}/%{NUMBER:haproxy.connections.retries:long} %{NUMBER:haproxy.server_queue:long}/%{NUMBER:haproxy.backend_queue:long} {%{IP:source.ip}|%{DATA:user_agent.original}|%{DATA:http.request.referrer}} "%{GREEDYDATA:haproxy.http.request.raw_request_line}"
Es muy importante que quede situado en la segunda posición, ya que el procesador usará la primera expresión que coincida e ignorará el resto.
En este momento deberían haber una lista de cinco patrones. Por último le damos al botón Update y a partir de ese momento los nuevos campos ya deberían ser visibles.
Espero que hayas disfrutado de este post y te animo a que revises nuestro blog para leer otros posts que puedan ser de tu interés. No dudes en contactarnos si deseas que te ayudemos en tus proyectos.
¡Nos vemos en la próxima entrada!