

Introducción
Consejos prácticos para sacar mayor provecho a CDK.
El nuevo framework de infraestructura como código que AWS ha desarrollado, CDK, está despertando mucho interés en el mundo DevOps por sus muchas ventajas. En Geko Cloud ya estamos utilizando CDK y consideramos que es una alternativa muy interesante a Cloudformation o Terraform. Para aquellos que quieren introducirse en el mundo DevOps o aquellas compañías que quieren implantar un modelo DevOps, donde los desarrolladores puedan desplegar la infraestructura que usaran sus aplicaciones, CDK es la herramienta perfecta ya que, a diferencia de otras herramientas de IaC permite utilizar lenguajes de programación conocidos por los desarrolladores reduciendo la curva de aprendizaje y facilitando su adopción.
Sin embargo, después de haber utilizado CDK en producción, y de varias lecciones aprendidas, la adopción de una herramienta tan sofisticada como es CDK no es tan sencillo como pudiera parecer en un primer momento. Por esta razón, hemos creado este post con la intención de explicar conceptos clave de CDK y a la vez compartir con vosotros consejos basados en nuestra experiencia para todos aquellos que os estéis planteando empezar a usar CDK o aquellos que ya lo estáis utilizando y os planteáis mejorar su uso.
Naming convention de Ids
En CDK existen muchos tipos de identificadores y cada uno tiene un propósito. Nuestra primera recomendación es que te informes sobre el funcionamiento de los
identificadores y la importancia que tienen a la hora de crear recursos en cloudformation. Los identificadores en CDK deben ser únicos dentro del contexto en el que son creados, lo cual tiene muchas y notables implicaciones.
Por ejemplo, puede utilizarse el mismo ID para dos constructs que se encuentran en dos stacks diferentes. Sin embargo, si intentas usar el mismo ID para dos constructs en el mismo Stack la aplicación devolverá un error al ejecutar algún comando de CDK como synth o deploy. Nuestro consejo aquí consiste en centralizar de alguna forma la generación de los identificadores, para que todos sigan la misma nomenclatura. Esto ayudará a no repetir identificadores y por otro lado facilitará la lectura de las templates de cloudformation creadas con CDK. Puedes utilizar una función helper que, dado un conjunto de parámetros, devuelve el identificador que se utilizará en los constructs, tal y como se muestra a continuación, aunque siéntete libre de usar el método que prefieras y con el que te sientas más cómodo.

Otro consejo es que intentes simplificar el naming convention que definas para los identificadores tanto como sea posible, ya que los identificadores lógicos y físicos que CDK genera, suelen ser muy largos e incluyen códigos hash que dificulta su lectura. Ten siempre presente que, una vez definido el naming convention para los identificadores de los diferentes recursos de tu aplicación, no deberías cambiarlo al no ser que sea completa y absolutamente necesario. Una vez has desplegado un recurso con un identificador, si el identificador cambia, el recurso será reemplazado por uno nuevo. Para que te pongas en contexto, supongamos que has creado una instancia RDS en producción y le has asignado un identificador. Si cambias el identificador de la instancia RDS en tu código de CDK, la próxima vez que despliegues en producción la instancia RDS será eliminada y sustituida por una nueva.
En el siguiente snippet de código de CDK se crea una instancia RDS:

Al desplegar este código, la instancia RDS se creará automáticamente como stack de cloudformation:
>Esta instancia ha sido creado con el identificador Pro-Geko-Cloud-RDS, los valores definidos para los atributos environment y project son los siguientes:

El template de cloudformation que genera CDK es el siguiente:

El logical name de la instancia RDS es ProGekoCloudRDS y un identificador hash concatenado como sufijo. Ahora modificaremos el método estático get_identifier para añadir el atributo dpt, como se muestra a continuación:
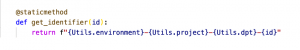
Tambien definiremos los siguientes valores:

Si ejecutamos un comando cdk diff podemos ver que hay cambios pendientes y que los cambios consisten en hacer un replace de la instancia RDS por una nueva instancia llamada ProGekoCloudsalesRDS.
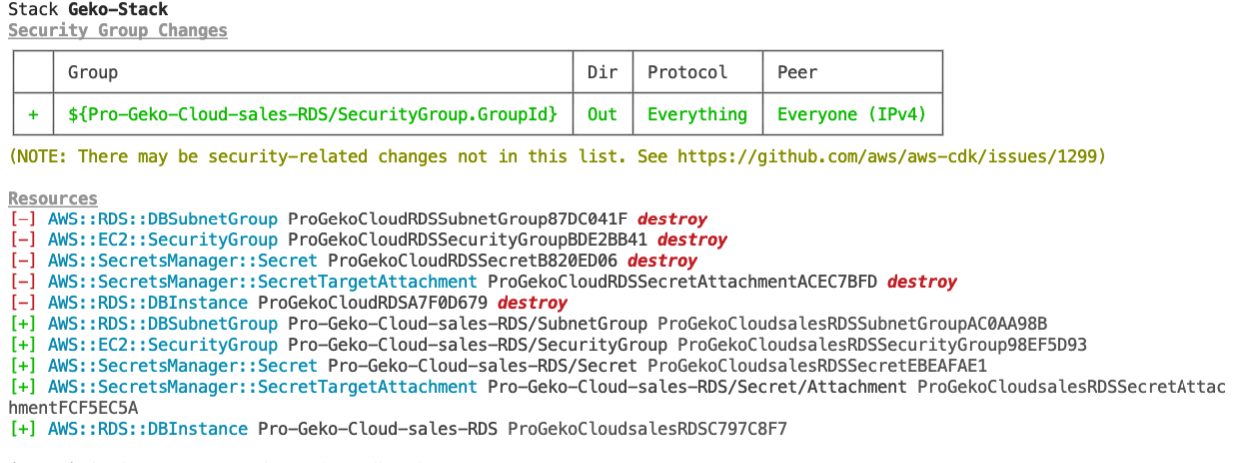
Como hemos visto, los identificadores son vitales para una aplicación de CDK. Antes de empezar a generar código fuente, define un naming convention y síguelo de manera estricta. Una forma de evitar cambios no deseados de identificadores consiste en ejecutar el comando diff de CDK en tu pipeline de deploy, como paso previo a desplegar tu infraestructura.
Por último, intenta no definir nombres para los recursos que provisiones en tu aplicación, deja que sea CDK quien elija los nombres de los recursos. Ten presente que hablo de nombres de recursos, no identificadores. En cloudformation, cuando realizas cambios sobre un recurso es posible que el recurso sea reemplazado porque los cambios que deseas realizar no son compatibles con el update del recurso. En este tipo de situaciones, es habitual que el update falle porque definistes un nombre a un recurso que tiene que ser reemplazado.
Si permites que CDK gestione el nombre de los recursos, en caso de que realices algún cambio que implica el replace de un recurso, CDK automáticamente reemplaza el recurso y le asignará un nuevo nombre. Si por el contrario, has definido el nombre del recurso, lo más probable es que el update falle.
Tagging
Añadir tags a los recursos en AWS es fundamental e indispensable. Las ventajas de utilizar tags son muchas y los inconvenientes nulos. En el caso de CDK esta máxima también se cumple y además os aseguramos que añadir tags en CDK es muy fácil como se muestra en la imagen siguiente:

Respecto a que tags utilizar, depende de varios factores, sin embargo, el tag Name se hace indispensable, sobre todo porque como hemos visto en la sección anterior, los identificadores que CDK asigna a los recursos pueden llegar a ser ininteligibles. Añadir un tag Name todos los recursos facilita mucho identificar recursos fácilmente. También podríamos utilizar el tag custom Owner para indicar el departamento que gestiona o que al menos paga la factura de AWS para los recursos creados. El tag Project es un clásico, se suele utilizar para identificar qué recursos pertenecen a qué proyecto. En cualquier caso, estés o no de acuerdo con estas recomendaciones, el principal consejo que os podemos dar es que definas una política de tagging que esté alineado con el compliance de tu compañía o equipo de trabajo porque te facilitará mucho la gestión de tu infraestructura, ya sea para localizar recursos o para identificar costes.
Testing
Hacer testing de tu aplicación es siempre una best practice y un buen consejo a seguir. Nos ayuda a encontrar errores con mayor facilidad, entregar software de mayor calidad e incluso puede ayudarnos a desarrollar con mayor agilidad si utilizamos metodologías de desarrollo como TDD. Para CDK existen dos tipos de testing que veremos a continuación.

Para implementar test en CDK necesitarás importar el módulo assertions. Si utilizas Python puedes utilizar Pytest para implementar tus tests.
Por otro lado están los snapshot tests. Estos test se utilizan cuando quieres refactorizar el código de tu aplicación CDK. El objetivo de estos tests es que a medida que haces modificaciones sobre tu código fuente verificar que todo sigue igual y que no hay cambios que puedan generar un problema a la hora de desplegar en producción porque el template de cloudformation que genera tu codigo CDK es el mismo que la última vez que lo ejecutaste. Para ejecutar test de tipo snapshot en Python tendrás que instalar la librería de python Syrupy. Una vez instalada ya puedes empezar a crear tus test de tipo snapshot:

Este test tiene dos parámetros, por una parte está el environment de CDK y por otro lado el parámetro snapshot que representa el template de cloudformation que se utilizará como referencia para ejecutar los test de tipo snapshot. Este parámetro lo gestiona la librería Syrupy, tu solo tienes que definirlo. El test ejecuta el stack donde se encuentra mi instancia RDS, obtiene el template de cloudformation y lo compara con el snapshot. Si el template no es igual que el snapshot el test falla. Al ejecutar un test del tipo snapshot por primera vez hay que definir el flag –snapshot-update, así:

Al ejecutar este comando, Syrupy creará una folder llamada __snapshots__ en tu folder de tests.

Dentro de la folder se guardará el template de cloudformation generado por el stack CdkGekoStack. Las siguientes veces que quieras ejecutar el test de tipo snapshot hay que ejecutar el comando python -m pytest sin el flag –snapshot-update. A partir de entonces, si el stack CdkGekoStack devuelve una template que no es igual que la template que Syrupy ha guardado en la folder __snapshot__ el test fallará.
Resumen
En este post hemos hablado de naming convention, tagging y testing. Conceptos tan básicos como necesarios. Os prometemos que en el próximo post: Consejos prácticos para sacar mayor provecho a CDK [Parte 2], hablaremos de conceptos más complejos como gestión de propiedades y constructs.
¡Estar muy atentos! Hasta entonces nos despedimos de vosotros.
Para más información no dudéis en contactar con nosotros.