

Queremos compartir con vosotros un problema que hemos resuelto recientemente con uno de nuestros proyectos.
RDS es el servicio de BBDD gestionadas que ofrece AWS, con el que resuelven los principales problemas de gestión, operación y mantenimiento que comporta tener una plataforma de bases de datos relacional. Con RDS todo es muy sencillo, garantizas el servicio y la operativa permitiendo crecer y decrecer según necesidad.
Además, Amazon tiene su propio motor basado en Mysql, Aurora, que incluso permite tener una plataforma de base de datos serverless, de la cual hablaremos en otro post más adelante.
El escenario que enfrentamos
Un cliente, con su plataforma full basada en AWS, con todas sus BBDD relacionales usando RDS, manifiesta en una de sus plataformas problemas de rendimiento, caídas, comportamiento errante y poco predecible, etc.
Dicho problema no ocurre desde el inicio del proyecto, sino que en cierto momento empezó a degradar hasta convertirse en un problema real. Apreciamos que RDS estaba desplegado usando instancia de bursting T3, dónde los créditos parecían decrecer de forma periódica.
Se opta por cambiar la instancia al tipo M5 para tener un mejor rendimiento y disponibilidad de recursos, tras lo cual la performance mejora muy sensiblemente hasta que advertimos lo siguiente:
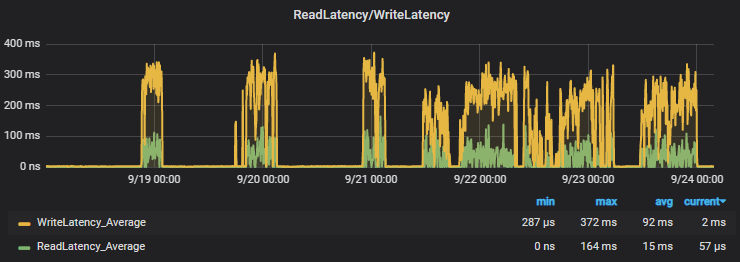
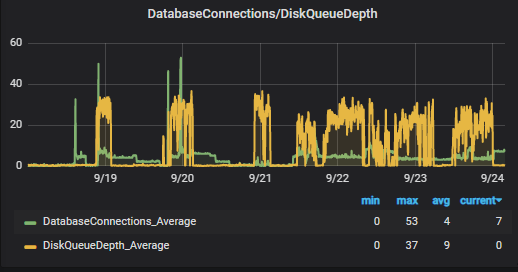
Las métricas siguen advirtiendo de que existe latencia de escritura/lectura y se encolan IOPS. ¿Cómo es esto posible en un disco SSD de uso general?
La métrica que para nosotros es importante seguir en cualquier RDS es la referente al Disk QueueDepth, esta métrica indica el tamaño de la cola que el sistema tiene en espera para ser procesada en operación IO de disco, es decir, la deuda en operaciones a disco que el sistema tiene. La latencia de disco de Read Write no es más que un espejismo de este hecho.
La solución
La explicación es simple, AWS RDS provisiona un total de 3 IOPS/Gb según el tamaño del disco EBS que se crea. La RDS del cliente se creó con 20Gb de tamaño total = 60 Provisiones IOPS , que AWS por defecto provisiona siempre un mínimo de 100 IOPS .
Esto explicaba el por qué la CPU y RAM no se veían afectados pero sí el rendimiento como tal.
En cuanto detectamos el cuello de botella, procedemos a ampliar mediante Terraform el tamaño del volumen EBS asociado a 100Gb, con sus correspondientes 300IOPS (el triple que antes).
El resultado lo tenéis aquí:
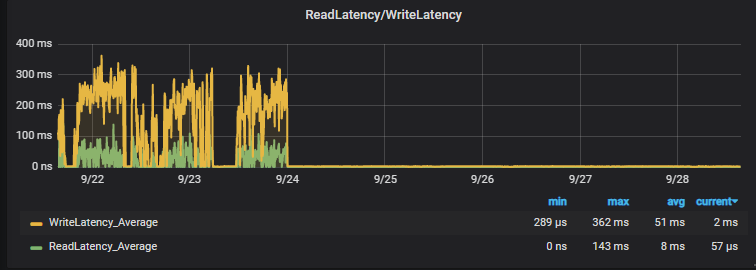
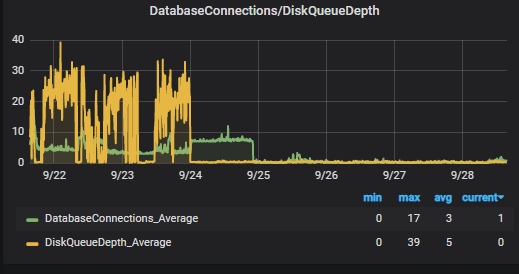
Nada más que añadir, se acabaron la latencias, los bloqueos y en general los problemas con esta plataforma, os dejamos el enlace a la documentación oficial de AWS sobre RDS y EBS
Recordad que para entornos productivos, la recomendación es siempre provisionar al menos de 100Gb el disco (aunque no nos hagan falta), para obtener esos 300 IOPS mínimo.
Recordad que en Geko seguimos a vuestra disposición para ayudaros con cualquier problema de rendimiento que tengáis con vuestra plataforma.