

Parcheado de equipos con Patch Manager
Introducción a SSM
SSM son las siglas de Systems Manager, un conjunto de herramientas que nos facilitan la vida, no sólo para acceder a las máquinas a través de una consola virtual, sino también para la ejecución de comandos remotos, extraer registros de los equipos, y como no, aplicar actualizaciones.
Con la suite de programas de SSM se pueden actualizar no sólo instancias EC2, si no también equipos on-prem, así como máquinas virtuales, equipos on-the-edge (IoT) como raspberrys, etc.
Systems Manager es un servicio que ejecuta un agente en el propio equipo (ec2 / on-prem, etc), del mismo modo que los agentes virtuales en entornos VMware, usados para extraer métricas de las instancias, pero en el caso de SSM la consola de gestión es remota, o lo que es lo mismo, se encuentra dividida en diferentes end-points. Es por ello por lo que el agente debe comunicarse con el servicio de SSM a través de red. Los equipos que quieran ser gestionados, deberán tener no sólo el agente instalado sino también conectividad de red para llegar a los endpoints de AWS SSM.
En este artículo hemos usado un par de instancias EC2 , una Linux y otra Windows:

Para la Linux hemos usado una AMI de RedHat, y en el caso del equipo Windows, se trata de la versión 2019.
Novedades de AWS Systems Manager (SSM) y Patch Manager 2024
AWS ha lanzado nuevas actualizaciones que mejoran la automatización y escalabilidad de SSM, haciendo que el parcheado en entornos multi-cloud y on-premise sea aún más eficiente. Entre las novedades destacan:
- Optimizaciones en tiempos de parcheado: Se ha mejorado la velocidad de instalación y actualización de parches, lo que reduce significativamente las ventanas de mantenimiento.
- Compatibilidad ampliada: AWS Systems Manager ahora soporta un mayor número de sistemas operativos, permitiendo gestionar más entornos desde una sola interfaz.
- Actualización automática de agentes: Una nueva funcionalidad permite actualizar el agente SSM de manera automática, garantizando que las máquinas gestionadas siempre operen con la versión más segura y eficiente del software.
Role para SSM
Para que el equipo pueda comunicarse con SSM, es necesario disponer de un role. Por ello vamos a generar un “service role” nuevo, accediendo al apartado IAM y seleccionado la opción “Roles” y clicando en el botón “Create role”:
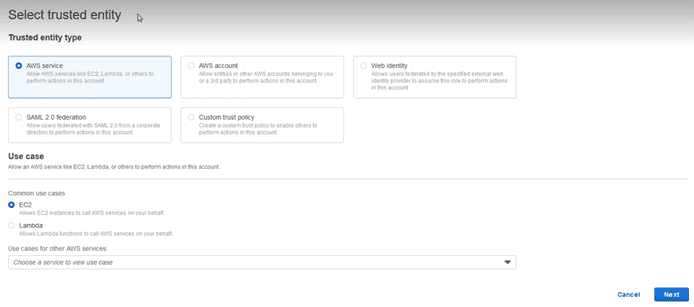
Seleccionamos como “Trusted entity” el “AWS Service”, y abajo en el apartado “Use case”, el servicio EC2. Seleccionamos siguiente y añadimos las políticas que son necesarias:
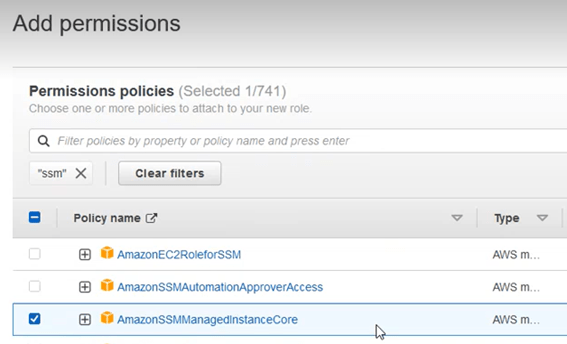
Para ello introducir en la casilla de búsqueda el nombre “ssm”, y escoger entre las opciones que aparecen la “AmazonSSMManagedInstanceCore”
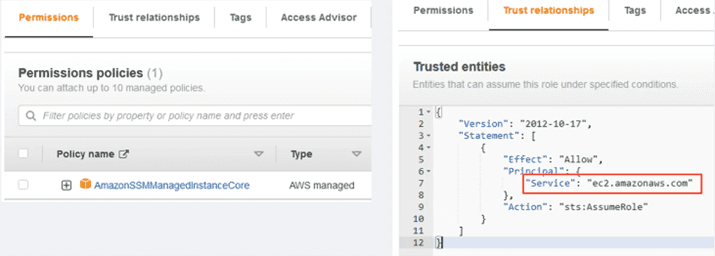
Asignamos el nombre que deseemos y nos aseguramos de que en el apartado de “trusted entities”, el valor de “principal” seleccionado es el servicio “ec2.amazonaws.com”, servicio con el que se va a invocar este role y al que estamos dando permiso:
El siguiente paso será añadir este role a las instancias. El modo más sencillo será marcar desde el panel la instancia a modificar, tal como se muestra en la imagen.
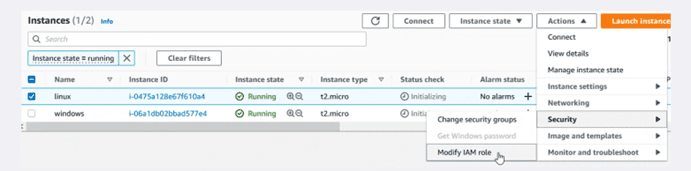
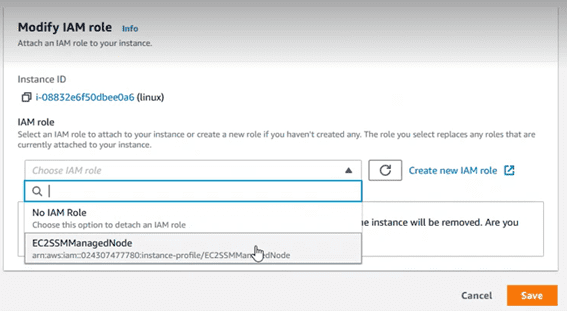
En el desplegable asignarle el role que acabamos de crear.
Nuevas amenazas de seguridad y la importancia del parcheado
En 2023, una serie de vulnerabilidades críticas, como la CVE-2023-30799, demostraron cómo los ataques a sistemas desactualizados pueden comprometer rápidamente la seguridad de las empresas. Esto subraya la importancia de mantener todos los equipos parcheados para mitigar riesgos. Los ciberataques que explotan vulnerabilidades en sistemas operativos, software empresarial y aplicaciones no solo generan pérdidas económicas, sino también daño a la reputación de la empresa.
La gestión de parches se convierte en una primera línea de defensa. Tener un sistema centralizado como AWS Patch Manager garantiza que no se pasen por alto actualizaciones críticas, eliminando puntos débiles.
Mejores prácticas en el parcheado de equipos
Hoy en día, la automatización inteligente y el uso de herramientas basadas en inteligencia artificial son tendencias clave en la gestión de parches. Algunas de las mejores prácticas incluyen:
- Priorizar parches con IA: Herramientas basadas en inteligencia artificial pueden analizar vulnerabilidades y recomendar qué parches son más urgentes, reduciendo la sobrecarga operativa y minimizando el riesgo de ataques.
- Simulación de vulnerabilidades: Realizar simulaciones para entender cómo una vulnerabilidad podría impactar a la organización permite priorizar la aplicación de parches. Las organizaciones pueden usar estas simulaciones para ajustar sus cronogramas de parcheado, asegurándose de que los sistemas críticos están protegidos primero.
- Pruebas en entornos de desarrollo: La implementación de canary testing es ahora más común. Con esta técnica, los parches se aplican primero en entornos de prueba antes de su implementación en producción, reduciendo el riesgo de interrumpir servicios críticos.
Automatización de la aprobación de parches: Para evitar el impacto negativo de parches no probados, se puede configurar la aprobación automática escalonada, donde los parches se aprueban para ciertos entornos (como desarrollo o pruebas) antes de ser aplicados en producción.
Instancias EC2 / managed nodes
En nuestro caso, hemos desplegado un equipo RedHat para la variedad Linux por un motivo: las AMI oficiales distribuidas por RedHat no llevan incorporado el agente, mientras que las AMI de Windows distribuidas por Microsoft o las AMI de Amazon Linux sí lo tienen.
La nueva funcionalidad de actualización automática de agentes permite que los equipos gestionados siempre cuenten con la última versión del agente SSM, lo cual mejora la eficiencia del parcheado y la seguridad de los nodos.
En caso de que nuestra distribución no tenga el agente, se puede instalar manualmente. Puedes revisar el siguiente enlace para ver qué distribuciones están soportadas:
Manual de instalación del agente SSM
Fleet Manager
Ahora que ya tenemos los equipos con el agente de SSM instalado y con el “service role” asociado, podríamos acceder al apartado de “fleet manager”, lugar donde se visualiza a modo de registro los equipos gestionados con SSM, tanto equipos EC2, como equipos on-prem, etc. Esta herramienta está dentro de las opciones de SSM:
Los equipos gestionados a través de SSM, reciben el nombre de nodos, es por ello por lo que, en la vista de este servicio, los equipos registrados se identifican en la columna de “Node Id”:

Los equipos que aparecen son los que están registrados en la región actual. Tener en cuenta que AWS SSM es un servicio regional, eso quiere decir que si tenemos una cuenta en varias regiones, será necesario repetir el proceso descrito en este artículo para cada región de manera independiente.
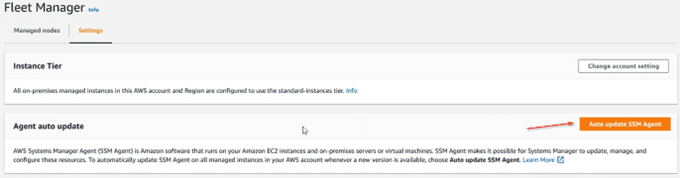
Como todo software, el agente de SSM recibe constantes mejoras. Es por ello recomendable habilitar en el apartado “settings”, la actualización automática:
Impacto en cumplimiento normativo
El parcheado constante también es fundamental para cumplir con normativas de seguridad como GDPR y las nuevas regulaciones de protección de datos. Empresas de todo el mundo deben asegurarse de que sus sistemas estén protegidos contra vulnerabilidades que podrían exponer información confidencial. El mantenimiento regular de sistemas y la capacidad de auditar el historial de parches aplicados se han vuelto componentes clave en auditorías de cumplimiento.
Tendencias recientes en ciberseguridad y parcheado
El enfoque Zero Trust ha ganado popularidad como estrategia de seguridad. Este modelo asume que ninguna entidad, dentro o fuera de la red corporativa, es de confianza, lo que hace que el parcheado continuo y la actualización de todos los sistemas sea aún más crucial. Con la federación de entornos multinube y la dispersión de recursos en diferentes plataformas, Patch Manager facilita la gestión centralizada de parches en un ecosistema diverso.
Baselines
Las “baselines” son manifiestos que definen un determinado nivel de cumplimiento con una política de seguridad. En el servicio de “patch manager” existen diferentes “baselines”, pero es muy recomendable crear propia una con las configuraciones que nos interese. Es un proceso realmente sencillo.
Para acceder al apartado de las “baselines”, ir a “Node Management” y seleccionar la opción “Patch Manager”:

Y en la pantalla que aparece acceder al botón “View predifined baselines”
En la vista de “baselines”, aparecen muchísimas, cada una para un sistema operativo diferente. Es en este momento cuando vamos a crear una personalizada. Para ello clicar sobre el botón “Create patch baseline”
En el nuevo apartado, seleccionar un nombre y una familia de SO que va a estar asociada a la “baseline”:

Definir la versión del SO, así como otros aspectos que definirán el nivel de cumplimiento:
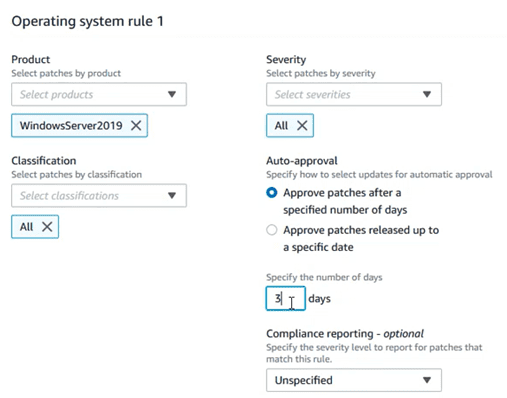
Hay opciones como el “auto approval”, que permiten aprobar la instalación de una determinada actualización, al cabo de unos días de su publicación, o a partir de una determinada fecha, evitando así que parches día 0, no muy testeados, pudieran romper la estabilidad de los equipos. Incluso esto permitiría tener equipos de PRE o TEST donde instalar parches días antes que en los equipos de producción a modo de “canary testing”.
Igual de importante es el apartado de excepciones de paquetes. Con ello se evita la instalación de determinados paquetes que pueden romper el servicio (sistemas con kernels compilados a mano, paquetes Windows que no se llevan bien con algún otro programa de terceros, etc).
Para añadir excepciones debe usarse el siguiente formato:

En este momento ya tenemos una “baseline” propia. Cuando las “baselines” son propias, para encontrarlas luego, hay que especificar que el propietario somos nosotros. Para ello en el buscador de baselines, especificar “Owner: Self” tal como se muestra a continuación:

De lo contrario la vista por defecto sólo muestra “baselines” estándar provisionadas por AWS.
Patch groups
Una vez tenemos definidas las “baselines”, vamos a definir los “patch groups”. Un “patch group” establece la relación entre las “baselines” y los equipos sobre los que se van a aplicar, en función del valor de un tag que especificaremos más tarde en los equipos.
Para crear un “patch group”, es muy sencillo, sólo tenemos que seleccionar la “baseline” que acabamos de crear, desplegamos el menú “Actions” y seleccionamos la opción “Modify patch groups”
Se abrirá un apartado para generar los patch groups, introduciendo un nombre. En nuestro caso “Windows_Production”

Una vez introducido el nombre, fijándonos en respetar la nomenclatura, clicamos en el botón “Add” y cerramos el asistente.
Tags
Los tags son metadatos que nos ayudan a identificar a quien pertenece un recurso, una unidad de imputación de costes, etc. En este caso, con los tags también podemos asociar los nodos a los “patch groups” correspondientes. Para ello se usa siempre el mismo valor de tag “Patch Group”. Ojo! Es “case sensitive”
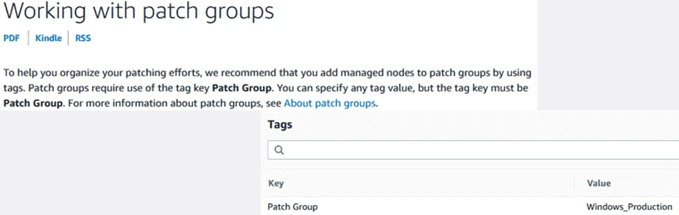
Vamos al apartado de las instancias, seleccionamos una de ellas, y editamos el apartado de tags para añadir el de “Patch Group”:
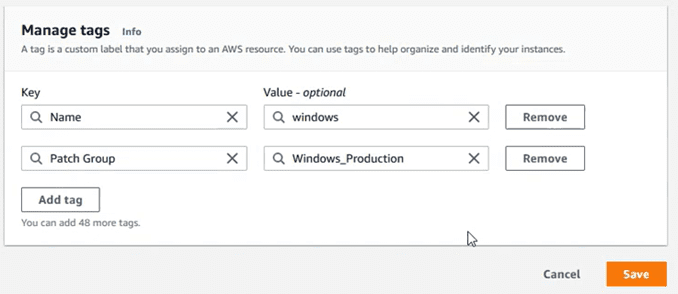
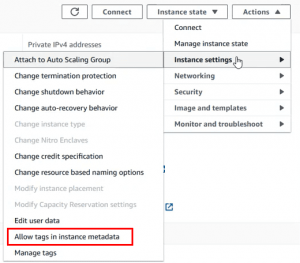
Si al introducir el tag, nos encontráramos con un error de tipo “’Patch Group’ is not a valid tag key.”

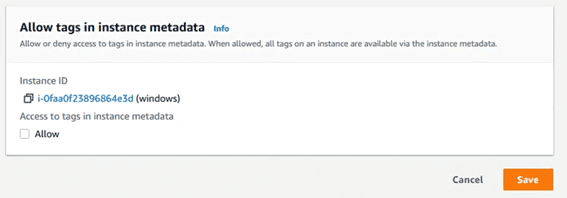
Es necesario deshabilitar la check box de metadata tagging en la configuración de la instancia:
Dejar la casilla siguiente deseleccionada y volver a probar a añadir el tag en el equipo.
Maintainance Windows
Recapitulemos. En este momento ya tenemos la instancia con el agente de SSM instalado y el role para interactuar con el servicio. Hemos creado una “baseline” propia, y luego la hemos asignado a unos “patch groups”. Finalmente hemos “tageado” las instancias con un tag que apunta directamente al “pach group” que nos interesa.
Las ventanas de mantenimiento son un apartado importante porque no sólo contiene la calendarización de las actualizaciones, sino también el listado de ejecuciones.
Vamos a proceder creando una ventana de mantenimiento a través del siguiente apartado:
Debemos introducir el nombre para la ventana, y fijar el cron. Se pueden establecer expresiones de cron con la nomenclatura típica o bien seleccionando las preestablecidas de cada hora o cada día.
Los valores de “Duration” y “Stop initiating task”, son obligatorios, y es recomendable dejarlos con unos valores como los siguientes:

Finalmente escoger zona horaria para hacer coincidir los horarios de la ventana con la que nos interese.
Al terminar tendremos un listado de las ventanas programadas, y datos interesantes como su próxima ejecución:

Configuración del parcheado
En este momento vamos a realizar el proceso que aglutina todos los pasos anteriores, y que capacita a “patch manager” para realizar las actualizaciones de los sistemas. Para ello acceder al apartado de “Patch Manager” y clicar en “Configure Patching”

Escoger los “patch groups” que se quieran actualizar:
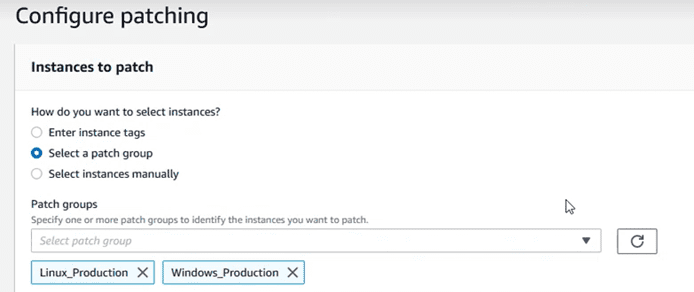
Escoger la ventana de mantenimiento que se ha creado en el paso anterior:
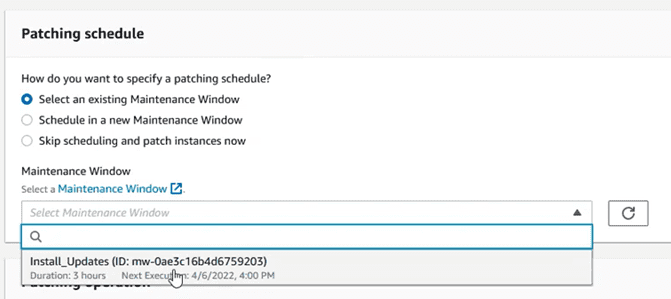
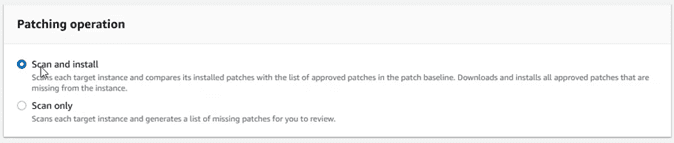
Y dejar la operación que más se ajuste a lo que queremos hacer. En este caso vamos a escoger “Scan and Install”
En este momento, en el “dashboard” de de “Patch Manager”, deberíamos tener una vista de equipos pendientes de actualizar. Los valores en este apartado irán cambiando en función de si hay paquetes pendientes, fallos en las actualizaciones, etc.
Para poder realizar un seguimiento de las acciones realizadas, las podemos consultar en el “Run Command”
En este apartado hay dos pestañas. Una con los comandos en ejecución en este momento, que saldrán con un reloj al lado:

Y otra pestaña con el histórico de acciones:
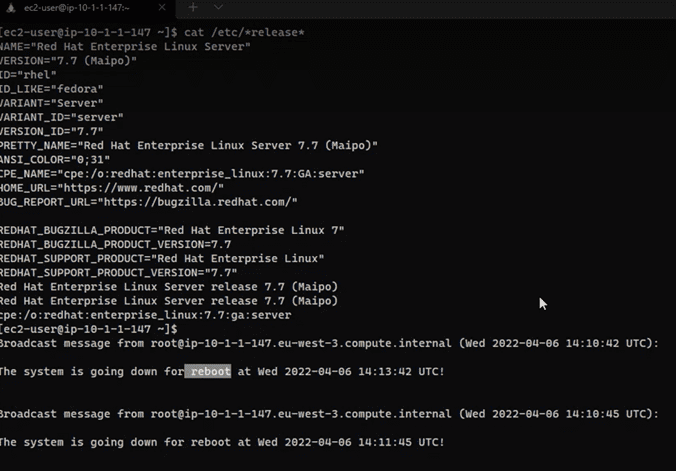
Si en el proceso de instalación de actualizaciones, hay algún paquete marcado como reinicio necesario, el equipo se reiniciará inmediatamente. Tener esto en cuenta para establecer las ventanas de acuerdo con las necesidades del negocio:
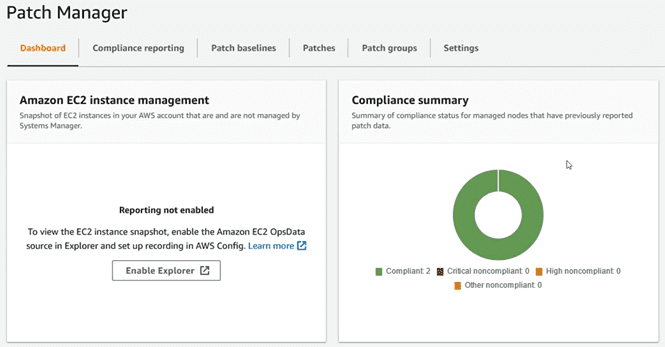
Tras la instalación de los parches, y los reinicios en caso de haberlos, en el “dashboard” de “Patch Manager” saldrán ahora las instancias como conformes de acuerdo a las “baselines” establecidas:
Cloudwatch
En la consola del histórico de comandos, podemos ver las tareas ejecutadas, como en este caso. Si clicamos sobre el id de la tarea, podemos acceder a su detalle:

Dentro podemos ver los equipos sobre los que se ha ejecutado la acción, y podemos , seleccionando uno de esos equipos, ver el detalle de las operaciones. Para ello seleccionar y clicar sobre el botón “View output”
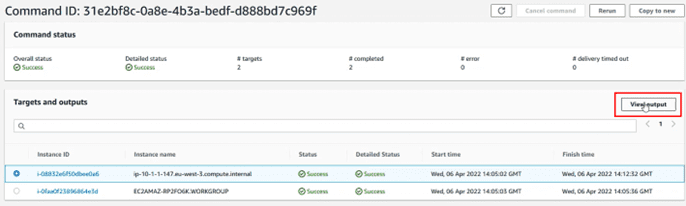
Las operaciones van probando todas las plataformas, por ello primero intentarán ejecutar el parcheado sobre un Windows, luego sobre un Linux y finalmente sobre un MacOS. Por ello para ver el estado de las actualizaciones, escogemos la plataforma del equipo que estamos consultando.
En la ventana “Output” veremos el registro, pero a menudo este se trunca por ser excesivamente largo:
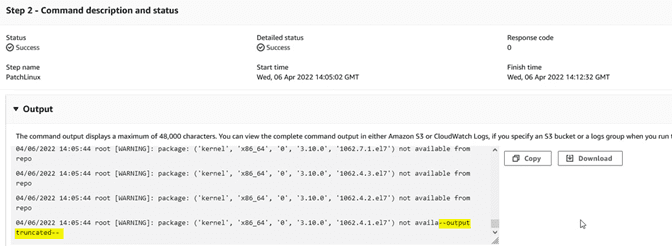
Si queremos consultar esos datos podemos enviarlo a un “log group” de Cloudwatch. Para ello, primero vamos a CloudWatch y creamos un “log group”:
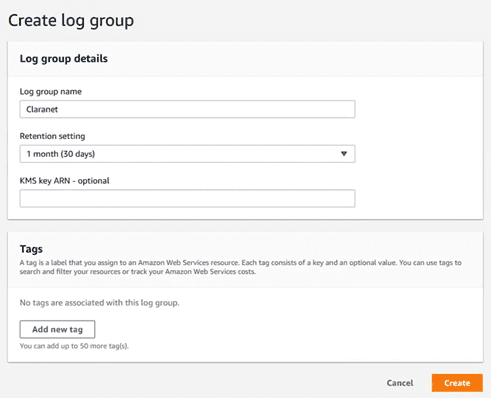
Ponemos un nombre y especificamos el periodo de retención.
El segundo paso es modificar el role de la máquina para que tenga permisos para escribir en Cloudwatch, por ello habrá que añadir una “in-line policy” como esta:

Le ponemos un nombre a esta “policy” y la guardamos:
Quedando el role del equipo como:
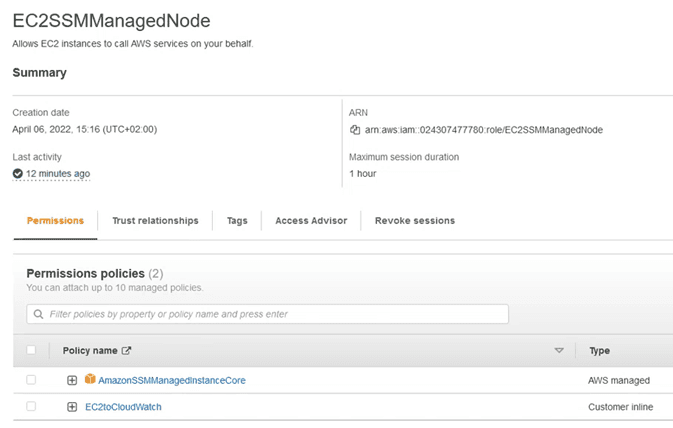
Volvemos a system manager, apartado “Mantainance Window” y dentro de las tareas (marco la tarea y selecciono edit):
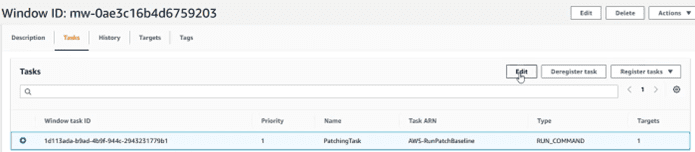
Y en el apartado “Output Options” , escribir el nombre del log group a donde lo vamos a enviar:
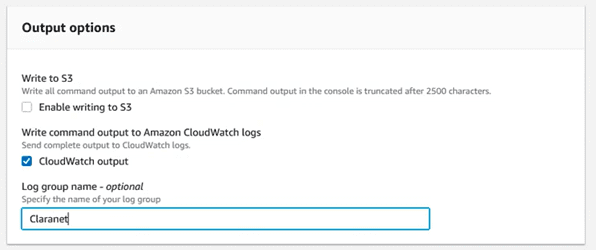
Guardamos los cambios, y a partir de ahora al seleccionar el output de las tareas, veremos que nos aparece un enlace hacia Cloudwatch:
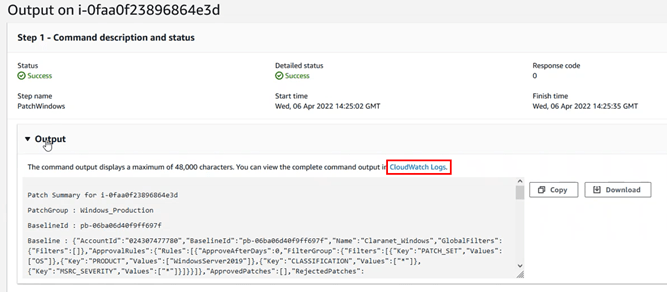
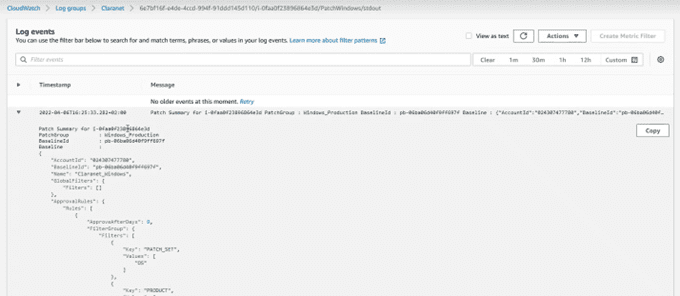
Y si consultamos ese enlace, nos llevará a la información de salida, pero ya sin truncar:
Con las mejoras recientes de AWS Systems Manager y Patch Manager, la gestión de parches se ha vuelto más eficaz, abarcando más sistemas operativos y mejorando la seguridad a través de la actualización automática de agentes. Estas mejoras, combinadas con buenas prácticas y la automatización, permiten a las organizaciones mitigar riesgos de seguridad y cumplir con las normativas más estrictas, garantizando la continuidad de sus operaciones.
¿Quieres saber más? Contacta con nuestro equipo