

Para resumir rápidamente un viaje FinOps, debemos centrarnos en tres fases:
- Información: saber en qué se ha gastado el dinero, es decir, visibilidad/asignación de costes.
- Optimización: optimizar los costes mediante la reducción de tarifas/estrategia de reducción de escala/…).
- Operar: mejora continua y supervisión de su estrategia FinOps, y automatización.
Para cada fase, intentaremos describir los conceptos clave y el mejor enfoque, en función del proveedor de cloud (principalmente Amazon Web Services y Microsoft Azure) y del entorno del cluster (producción/no producción).
Informar
En el mundo de Kubernetes y especialmente con los servicios gestionados, asignar costes puede ser una auténtica pesadilla porque para hacerlo bien hay que tener en cuenta e identificar múltiples recursos: por un lado, respecto a Kubernetes como los pods, pero también a nivel del proveedor Cloud (y teniendo en cuenta costes como balanceador de carga/nodo/almacenamiento/red/…)
La asignación de costes es el proceso de dividir facturas y asociar cada parte a un centro de costes, que podría ser una aplicación/departamento/equipo e intentar obtener la mayor precisión posible. De este modo, se obtiene una mayor visibilidad de los costes. En un entorno de nube, esto no es fácil porque algunos recursos se comparten entre muchos centros. Por otro lado, también hay que gestionar descuentos como reservas, ancho de banda de red y muchos otros elementos.
Para lograrlo, se utilizan etiquetas para identificar al propietario de los recursos (por ejemplo, aplicación1) y, a continuación, es necesario establecer una estrategia adicional para asignar los elementos no etiquetados.
Además, los proveedores cloud cobran a nivel de host (con la excepción de AWS EKS que se ejecuta en modo Fargate completo y GKE Autopilot), no a nivel de contenedor. Por lo tanto, debe asignar una cantidad determinada de recursos de host (vCPU/Memoria/…) a cada contenedor y, a continuación, resumirla en función de su estrategia de aplicación de etiquetas. También debes tener en cuenta los «costes compartidos», como el coste primario de Kubernetes, y los «costes ociosos» (porcentaje de recursos de host no utilizados). No puedes utilizar el servicio de gestión de costes de un proveedor de nube común, como AWS Cost Explorer o Azure Cost Management, para crear la distribución de costes.
Utilizar una herramienta de terceros como Cloudhealth podría ser útil en tu tarea de distribución de costes, pero la realidad es que tiene un coste elevado, a menos que puedas utilizar herramientas como Kubecost para obtener una estimación de la distribución de costes (funciona con AWS y GCP).
No existe una estrategia única que funcione en todos los casos, tienes que encontrar la que mejor se adapte a tu caso de uso. Estas son algunas de las pautas:
- Hay que definir una estrategia de etiquetado. Debe ser la misma que la definida respecto al proveedor de la nube.
- Utiliza Kubernetes Labels con tu estrategia de etiquetado definida para la asignación de costes.
- Agrupa contenedores mediante espacios de nombres de Kubernetes para simplificar la asignación de costes.
Optimizar
La fase de optimización se centra en los procesos de reducción de costes. Algunos de ellos pueden aplicarse independientemente del proveedor de la nube, pero otros dependen de especificaciones.
Podemos agrupar las optimizaciones en cuatro categorías:
- Rightsizing: asignar la cantidad adecuada de recursos (vCPU/Memoria) a hosts y pods.
- Off-hours: desconectar o reducir recursos durante las noches y los fines de semana.
- Spot node: utilizar instancias spot para nodos Kubernetes.
- Reserva de nodos: comprar una instancia/máquina virtual (o planes de ahorro para AWS).
A modo de guía rápida, te compartimos el siguiente diagrama, en el que puedes encontrar el orden de las optimizaciones recomendadas en función del entorno del cluster (producción o no producción):
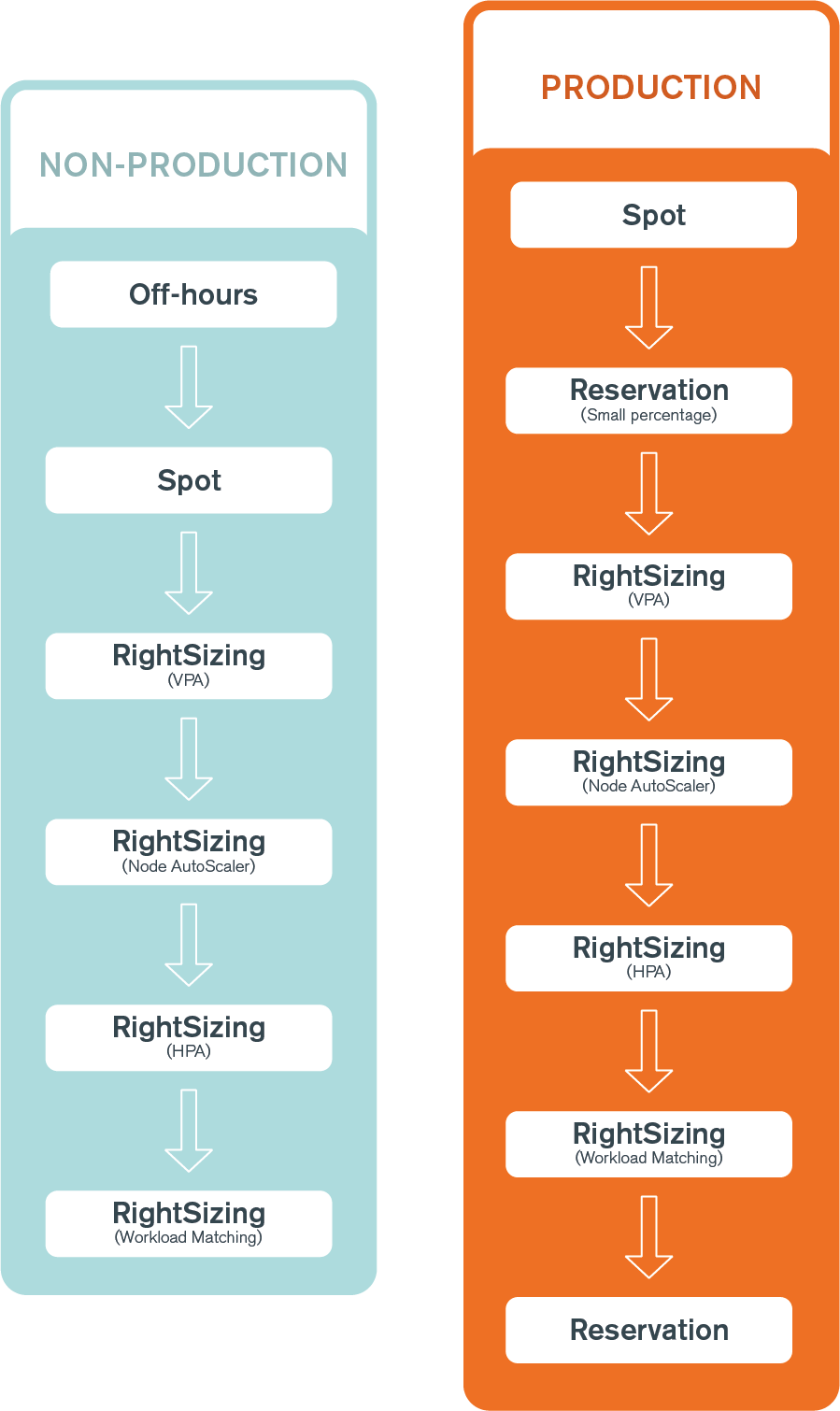
Redimensionar
El redimensionamiento puede realizarse a nivel de pod/contenedor y/o a nivel de host/nodo.
Nota: redimensionar significa ajustar las capacidades de los recursos, pero también añadir/eliminar recursos idénticos.
Contenedor
En el mundo de los contenedores, existen varias estrategias de escalado: Escalado horizontal (HPA)
Al igual que un grupo de autoescalado de EC2 o Azure VMSS, el escalado horizontal tiene como objetivo añadir o eliminar recursos (pods en este caso) para mantenerse al día con la carga de trabajo actual.
Kubernetes Horizontal Pod AutoScaling está diseñado para aplicaciones sin estado, que pueden iniciarse rápidamente para gestionar picos de uso y detenerse con elegancia.
Escalado vertical (VPA)
A diferencia del escalado horizontal, que añade o elimina pods, el escalado vertical puede aumentar o disminuir los recursos de los pods (CPU/Memoria) tras un periodo de evaluación.
El autoescalado vertical de Kubernetes es especialmente útil para ajustar las demandas de CPU y memoria al consumo real de los contenedores. A menudo, las demandas de los contenedores están sobredimensionadas, desperdiciando recursos.
VPA puede ajustar automáticamente los recursos de los contenedores. Sin embargo, no es recomendable. Tómalo como consejo y luego ajusta tus definiciones de recursos de Kubernetes.
Redimensionamiento de nodos
Tus pods utilizan recursos de nodo, por lo que cuando utiliza HPA o VPA, es obligatorio poder ajustar su capacidad.
El Kubernetes Cluster Autoscaler puede añadir o eliminar nodos para optimizar la capacidad de los recursos del cluster.
El PodDistruptionBudget es un elemento esencial cuando se activa el cluster Autoscaler para evitar el tiempo de inactividad de la aplicación.
Otro concepto importante relativo al escalado de nodos es la coherencia con la carga de trabajo. Esto significa que se debe tener en cuenta la relación CPU/memoria de su nodo para evitar tener demasiada memoria o CPU sin utilizar. Por ejemplo, tus pods consumen más memoria que CPU, pero la capacidad de los nodos es más o menos igual. En este caso, estarás malgastando recursos de CPU y aumentando el coste de tu infraestructura. Para evitarlo, cambia el tipo de instancia de nodo a una instancia optimizada para memoria.
Para detectar el problema de coherencia con la carga de trabajo, comprueba el «uso solicitado de CPU» y el «uso solicitado de memoria». Por ejemplo, tienes un problema si el «uso de CPU» es del 100% mientras que la «demanda de memoria» es solo del 50%.
Fuera de horario
Fuera de hora significa detener o reducir la capacidad de los recursos por la noche (y los fines de semana). Para los entornos que no son de producción, debería ser la norma.
Parar los recursos entre las 8 de la tarde y las 7 de la mañana y los fines de semana tiene una ventaja, y es que reduce el coste en un 60%.
kube-downscaler es el punto de entrada para clusters de producción y no producción (debe combinarse con Cluster Autoscaler para ahorrar dinero).
Este proyecto de código abierto reducirá los despliegues/clusters estáticos/HPA basándose en políticas definidas (tiempo/no conforme con condiciones de exclusión como la restricción del espacio de nombres).
Producción
En un entorno de producción, debes asegurarte de que, incluso fuera de las horas de trabajo, tu cluster/aplicación cliente permanece altamente disponible y tolerante a fallos:
- Tiene al menos 2 réplicas de cada aplicación crítica.
- Distribuidas en al menos 2 nodos.
No se trata realmente de horas valle, sino de una reducción de escala cuando disminuye la carga del cluster.
No producción
Un cluster que no sea de producción debería poder escalarse hasta 0 trabajadores, pero con los clusters Kubernetes gestionados, algunos servicios en la nube tienen limitaciones (ver más abajo).
cluster-turndown es un proyecto de código abierto que facilita la realización de operaciones fuera de producción. Actualmente, el proyecto es compatible con GKE, EKS y KOPS en AWS.
AWS EKS
Puedes reducir el número de trabajadores (grupo administrado o no administrado) a 0, pero no olvides que AWS sigue cobrando por la administración del cluster.
AZURE AKS
Azure AKS es diferente a AWS porque Azure no cobra por la gestión del cluster (a menos que añadas la opción uptime SLA.sta opción no tiene sentido para un cluster que no sea de producción), pero no puedes reducir el grupo de nodos por defecto (sistema) a 0.
El coste depende del tamaño de la máquina virtual. Para los pools de trabajadores, puedes reducirlos a 0.
Nodo spot
Los Spot Nodes son otra buena forma de reducir el coste de los clusters Kubernetes. En general, las instancias/máquinas virtuales spot son recursos «normales» que se benefician de un descuento significativo. Pero este descuento tiene un inconveniente: los proveedores de la nube no garantizan la disponibilidad de estos recursos. Pueden interrumpirse en cualquier momento.
Esto significa que las aplicaciones en ejecución deben ser tolerantes a fallos para un entorno de producción (fuera de producción, esto no es obligatorio, pero debes aceptar el riesgo de tiempo de inactividad hasta que un nuevo nodo esté listo).
Cada proveedor de nube ofrece una forma de recibir una notificación (API de metadatos local) unos segundos/minutos antes de que el nodo se apague. Esto mitiga el impacto del apagado del nodo.
Para utilizar con éxito los nodos spot, es ideal considerar el uso de:
- node affinity y anti-affinity (identificar pods que puedan soportar/desplegarse en nodos spot).
- Kubernetes cluster-autoscaler con la función de expansión del cluster-autoscaler (para volver automáticamente al tipo bajo demanda si no hay más spots disponibles).
- la función MixedInstancePolicy de cluster-autoscaler [toma diferentes instancias (deben tener la misma capacidad de CPU y Memoria) para mejorar la disponibilidad de Spots. Exr5.2xlarge/r5a.2xlarge/r5d.2xlarge/r5ad.2xlarge/i3.2xlarge)] – solo AWS
AWS anunció la compatibilidad con instancias spot en un grupo de nodos administrados. Con esta nueva característica, el drenaje de nodos y la estrategia de instancias spot son gestionados por AWS. Además, ofrece unaestrategia de asignación de capacidad optimizada yreequilibrio de capacidad, dos características interesantes para los grupos de Spot AutoScaling.
Azure tiene algunas limitaciones/condiciones para utilizar los nodos spot:
- El pool de nodos por defecto (sistema) no admite Spot Nodes (y debe tener al menos 1 VM).
- No puede mezclar nodos estándar y nodos spot en el mismo pool de nodos.
- Debe crear uno (o más) pool de nodos estándar y otro (o más) pool de nodos spot.
Producción
El consejo más común para utilizar nodos spot en un cluster de producción es distribuir la capacidad de nodos entre nodos bajo demanda/estándar y nodos spot para evitar sufrir un apagado completo si los nodos spot no están disponibles. La distribución depende principalmente de las aplicaciones alojadas.
Por ejemplo, la distribución podría ser
- 30% Spot – 70% A la carta/Estándar
- 50% Spot – 50% A la carta/Estándar
- 70% Spot – 30% A la carta/Estándar
Fuera de producción
En un entorno fuera de producción, la estrategia de distribución puntual puede ser mucho más agresiva que en producción, ya que no es necesaria una disponibilidad absoluta. Incluso puede apuntar a la distribución solo con nodos puntuales. En caso contrario, como en un entorno de producción, elige un equilibrio entre bajo demanda/estándar y puntual.
Producción
Para un cluster de producción debes iniciar el proceso de reserva lo antes posible. Puedes empezar poco a poco reservando solo, por ejemplo, el 10% de tu capacidad e ir reservando más con el tiempo.
AWS
Utilizar AWS Fargate (parcial o totalmente) es una elección fácil, ya que solo los planes de ahorro informático pueden cubrir tanto EC2 como Fargate.
Alternativamente, si tienes una mezcla de instancias On-Demand y Spot, puedes elegir cubrir el 100% de tu On-Demand y si no tienes una instancia Spot, depende de la carga del cluster.
Azure
El punto de partida es comprar máquinas virtuales reservadas para el conjunto de nodos por defecto (sistema). Si tienes una mezcla de instancias Standard y Spot, puedes elegir cubrir el 100% de tu instancia Standard y si no tienes una instancia Spot, depende de la carga del cluster.
Con la función de cancelación de reservas, puedes ser realmente agresivo en la cobertura de reservas, ya que el punto de equilibrio se alcanza rápidamente (los gastos de cancelación son sólo el 3% de los gastos de reserva restantes). Consulta la documentación de Azure para obtener más información.
No producción
AWS
Si no ejecutas tu cluster únicamente con nodos de subasta y no cambias a grupos de 0 nodos durante las noches o los fines de semana, puedes reservar el número mínimo de nodos operativos.
Azure
Como no puedes reducir el pool de nodos por defecto (sistema) a 0, puedes adquirir máquinas virtuales reservadas para cubrirlos.
En el caso de los pools de nodos de trabajo, si los reduces a 0 durante las noches/los fines de semana, no puedes comprar reservas. Como alternativa, puedes reservar el número mínimo de nodos de trabajo.
Con la función de cancelación de reservas, puedes ser muy agresivo en la cobertura de reservas, ya que el punto de equilibrio se alcanza rápidamente (los gastos de cancelación son sólo el 3% de los gastos de reserva restantes). Consulta la documentación de Azure para obtener más información.
Particularidades de AWS Fargate
Obligatorio:
- Solo cargas de trabajo interrumpibles.
Limitaciones:
- Statefulset no soportado (usar EFS para volumen persistente)
- No está disponible en todas las regiones de AWS
- Solo admite ALB como tipo de balanceador de carga
- Máximo 4vCPU y 30GB de memoria por contenedor
Opciones:
- Fargate
- Fargate con instancias puntuales
Modelo de precios
- Por vCPU por hora y por memoria (GB) por hora.
Fargate es un buen candidato para:
- Clusters muy pequeños
- Pruebas rápidas/POC
Operar
La fase de operaciones permite mejorar continuamente tu estrategia FinOps. Sus controles permiten:
- Cambios en los costes globales
- Cambios en los costes elemento por elemento
- Dar a los desarrolladores los medios para supervisar su uso de Kubernetes y animarles a hacerlo.
- Utilizar las últimas funcionalidades del proveedor de Cloud (por ejemplo, disponibilidad de la instancia/vm de nueva generación)
- Comprobar si se pueden aplicar nuevas optimizaciones
Esta es una lista no exhaustiva de cosas que hay que hacer/comprobar durante la fase de operaciones, que DEBEN llevarse a cabo en entornos de producción y de no producción.
Si quieres saber más sobre recursos útiles relacionados con Kubernetes desde la perspectiva de FinOps, aquí te dejamos nuestras recomendaciones:
- Mejores prácticas de Google Cloud para ejecutar Kubernetes de forma rentable
- Libro blanco FinOps para Kubernetes de la FinOps Foundation
¿Necesitas ayuda? Contacta con nuestro equipo.