

Introduction
Nowadays is more and more common for companies to migrate some parts of their infrastructure —or even the entire company— to the cloud. There are two main approaches: Stay as close as possible to the previous architecture by using VMs, or bet for flexibility/scalability/availability and go for a new perspective by using a container orchestrator like Kubernetes. Focusing on this latter approximation (Kubernetes), what you previously had running on an Operative System (which had access to mostly all the conveniences an Operative System provides) now runs in containers. In addition, these containers don’t commonly run directly on specific targets (or machines), but on a cluster. Everything works cool and everything is awesome until you realize you’re not in a friendly and well-known environment anymore. Operative System’s tools like automated tasks or Cron don’t actually follow the containers’ best practices, as they are system-wide (which is the opposite to the app-isolation approach the containerization prays for). Embed those tools (or their behaviors) on your isolated application could become into a big pain full of workarounds and not-that-good practices.
As a full huge ecosystem, Kubernetes provides some of these functionalities so the day-to-day requirements could be addressed. However, brand-new operatives come into the scene when talking about clusters, containers, and a big variety of workflows to handle. Across the following lines, you will learn how Kubernetes have solved the Cron functionality, and most of its tricky, hidden features.
1. How Kubernetes CronJobs actually work
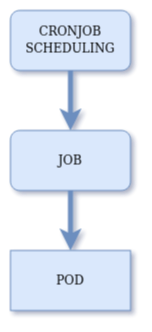
When a CronJob resource is created, what Kubernetes actually does is to register a schedule. Every 10 seconds the CronJob Controller checks if there are matching schedules to take care of. When the proper time arrives a new Job resource is created to handle the task for that specific run. Finally, every Job creates a Pod in order to run the task.
As you may notice this approach differs significantly from the OS one. What is actually happening here is a decoupling between cron-schedules’ handling and the task’s handling (Jobs). This allows the cluster (and also you) to handle ephemeral tasks without loosing control over them.
Moreover, Jobs can create one or more Pods (allowing concurrency/parallelism) and they also ensure the tasks are successfully accomplished. However, this last behaviour could create additional issues as the container also offer a restart-handling feature. This topic will be addressed on the following section.
2. How to configure the advanced functionalities
First of all it must be taken into account that in order to configure a CronJob, every underlying resource could be configured as well. This means a CronJob configuration aggregates its own parameters plus the Job’s properties and also the Pod/container specifications. As most of the common work-flows can be addressed just by having a quick look at the documentation, the aim of this section is to show how to achieve certain tricky functionalities through configuration.
Errors’ handling
When a container stops its execution (because of a failure or after a successful execution) there are a set of actions that could be taken just after, which are defined —as usually— by resource directives. Typical actions are restarting the container (always or only when a failure is detected) or doing nothing. Moreover, the Jobs add another complexity layer which ensures the task is successfully terminated. This means the restarting policy is guaranteed through two different layers that must be properly configured to achieve the desired behavior.
On the container side, the directive is called restart Policy. On the Job side, this policy is “handled” by the directive back-off limit, which specifies the number of allowed failures before giving up and stopping to restart the task. Keeping that in mind, setting up a CronJob able to fail without restarts is as easy as follows.
apiVersion: batch/v1beta1
kind: CronJob
...
spec:
...
jobTemplate:
spec:
backoffLimit: 0
template:
spec:
containers:
...
restartPolicy: Never
Overlapping vs. Sequential executions
When talking about a specific CronJob, multiple runs of it could coexist. Depending on the kind of flow the task is characterized for, concurrency could be a way to proceed in order to speed-up processing. There are three available ways to handle how the Jobs are run, which are controlled by the directive concurrency Policy.
- Allow: Allow overlapping executions.
- Replace: New executions terminate the previous ones before starting.
- Forbid: New executions are discarded if a previous one is still running.
While the first one allows concurrence, the two last ones bet for sequential executions. Once again, to stay as close to old-fashioned crons the closer approach is to set the Allow policy. On the other hand, concurrent runs could cause undesired effects if they are not properly managed, and it’s something that should be kept in mind and also be handled with care.
Minimum execution time
As it was previously stated, new task executions could interfere with previous ones depending on how the concurrency directives are set. There’s a property from the container specification which could be useful to deal with the consequences of interrupted runs. A minimum execution time can be set through the terminationGracePeriodSeconds container-property so even if another new task causes an old one to finish, a graceful termination is guaranteed.
3. Operating the CronJobs as a Master
Once the configuration shows up what the CronJob was intended to do, the basic commands can be issued to retrieve the status (scheduling info, running state, logs, …). As on the previous section, the following operatives will cover how to achieve some uncommon features.
Enable/disable CronJobs
The CronJob’s specification has a property called suspend which allows to deactivate them. Temporarily or not, CronJobs can be defined but not being executed at certain times (as their schedule states).
# Disable a CronJob
CRONJOB_NAME=my-cronjob-1
kubectl patch cronjobs $CRONJOB_NAME -p '{"spec" : {"suspend" : true }}'
# Disable ALL CronJobs
kubectl get cronjobs | grep False | cut -d' ' -f 1 | xargs kubectl patch cronjobs -p '{"spec" : {"suspend" : true }}'
Have a look at the following section in order to get further details about the side effects this could cause.
Run CronJobs manually
It’s widely known testing is very useful when detecting undesirable effects. CronJobs can be run manually even when they are suspended (deactivated), so keeping them in that state and running them under testing circumstances could help to validate everything is correct.
CRONJOB_NAME=my-cronjob-1 kubectl create job --from=cronjobs/$CRONJOB_NAME $CRONJOB_NAME-manual-exec-01
4. Showing up the edge cases
After all, there would be no variety if everything were the same way. Every situation has its own particularities and specific characteristics, so when talking about CronJobs that will not be different. Across the following lines, some edge cases will be presented and addressed, so the solutions to them could be reused (or —at least— taken into consideration).
Maximum execution time
On previous sections the execution-time topic was addressed to guarantee a graceful time is conceded before termination. But hey! What about the tasks taking too much time to finish? Agnostic containers’ motivation (and also the Kubernetes one) is to run the tasks until the infinity and beyond. Containers can flow or they can crash, but they should never be terminated as a common practice. Following this principle, there is no way to manage timeouts from the CronJobs/Jobs/Containers specification. So, it’s impossible to handle a maximum execution time? — No, it isn’t! Hence is where the Linux tool-set comes to the rescue. There’s a command called timeout that could be used to run another command until a specific amount of time.
Even though the previous utility could limit the time, the exit code when it does it’s not a successful one so the container will enter into a failure status (that could escalate to a restart if it’s allowed to). On the other hand, the command status could be preserved but then it can’t be known if it was terminated or not. So, how to address them all? On the following snippet can be found a suggested approach that manages to always finish successfully while giving feedback about what actually happened.
containers:
- name: "my-time-limited-to-10s-container"
...
command: ["bash", "-c"]
args:
- /usr/bin/timeout 10 bash -c 'bash -c "comm arg1" && echo OK || echo KO-COMM' || echo KO-TIME
CronJobs not being scheduled after being disabled and enabled again
There is a side effect when a CronJob is disabled, which is that after 100 missed schedules the CronJob will no longer be scheduled. This is already on the docs, but it’s just mentioned as something else not very important. The solution here is to recreate the resource.
CronJobs being scheduled out of their schedule just after being enabled
Another unexpected effect you may find when dealing with CronJobs is that when reactivating one of them —despite that time doesn’t match the schedule— it is immediately executed. This happens because the execution is not just an isolated event, but a time-window until a deadline. This means every missed schedule (because of concurrency or because the CronJob is disabled) will increase a counter (up to a certain number, which is something that could be related to the previous edge case). Then, when the CronJob gets reactivated and it’s allowed to run, the controller realizes there are pending schedules. If the time window to the deadline is still not closed, the CronJob begins to run.
This behavior can be addressed by setting the startingDeadlineSeconds directive to a small value, so the execution window will not match the reactivation time.
CronJobs is not being scheduled
It comes the startingDeadlineSeconds directive could be set to any value, but not all of them are going to cause the desired effect. As previously said the CronJob‘s controller runs every 10 seconds, so every value below ten seconds will make the CronJobs never be scheduled. An issue has been submitted by us to the Kubernetes website project, in order to warn them about this effect. In the next versions you will probably find out it’s already documented, but not for now.
So don’t forget to set startingDeadlineSeconds to a value greater than 10.
Conclusion
As you may have seen, the difference between OS’ crons and Kubernetes‘ crons is bigger than it could be expected at first looking. There are several scenarios on a cluster and many situations to handle, so they are addressed. Sometimes we will be looking for a OS-like behavior, sometimes not, but probably all of them will be possible to achieve. On the other hand, being so multi-purpose could end (as on CronJobs) on more difficult configuration experience, which could be even more difficult when the docs are a little bit short and vague.
Thankfully, you can always count on Geko team -a high-skilled engineering team- who will dig on the topic until getting it easy for you. Don’t forget to come back to the Geko’s blog and check out what’s new in here! The Geko team will be always glad to see you back, and also you should contact us for further information!
Further reading
https://kubernetes.io/docs/tasks/job/automated-tasks-with-cron-jobs/
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
https://kubernetes.io/docs/concepts/workloads/controllers/job/
https://www.magalix.com/blog/kubernetes-patterns-the-cron-job-pattern
https://medium.com/@bambash/kubernetes-docker-and-cron-8e92e3b5640f
https://medium.com/cloud-native-the-gathering/how-to-write-and-use-kubernetes-cronjobs-3fbb891f88b8
https://medium.com/@hengfeng/what-does-kubernetes-cronjobs-startingdeadlineseconds-exactly-mean-cc2117f9795f